Despite constant advances and seemingly super-human performance on constrained domains, state-of-the-art models for NLP are imperfect. These imperfections, coupled with today's advances being driven by (seemingly black-box) neural models, leave researchers and practitioners scratching their heads asking, why did my model make this prediction?
We present AllenNLP Interpret, a toolkit built on top of AllenNLP for interactive model interpretations. The toolkit makes it easy to apply gradient-based saliency maps and adversarial attacks to new models, as well as develop new interpretation methods. AllenNLP interpret contains three components: a suite of interpretation techniques applicable to most models, APIs for developing new interpretation methods (e.g., APIs to obtain input gradients), and reusable front-end components for visualizing the interpretation results.
This page presents links to:
- Masked Language Modeling using BERT, to explain why it made certain mask predictions.
- Textual Entailment and Sentiment Analysis using ELMo-based LSTM classifiers.
- SQuAD and DROP reading comprehension using an ELMo-based QANet
- NER using an LSTM-CRF model based on ELMo.


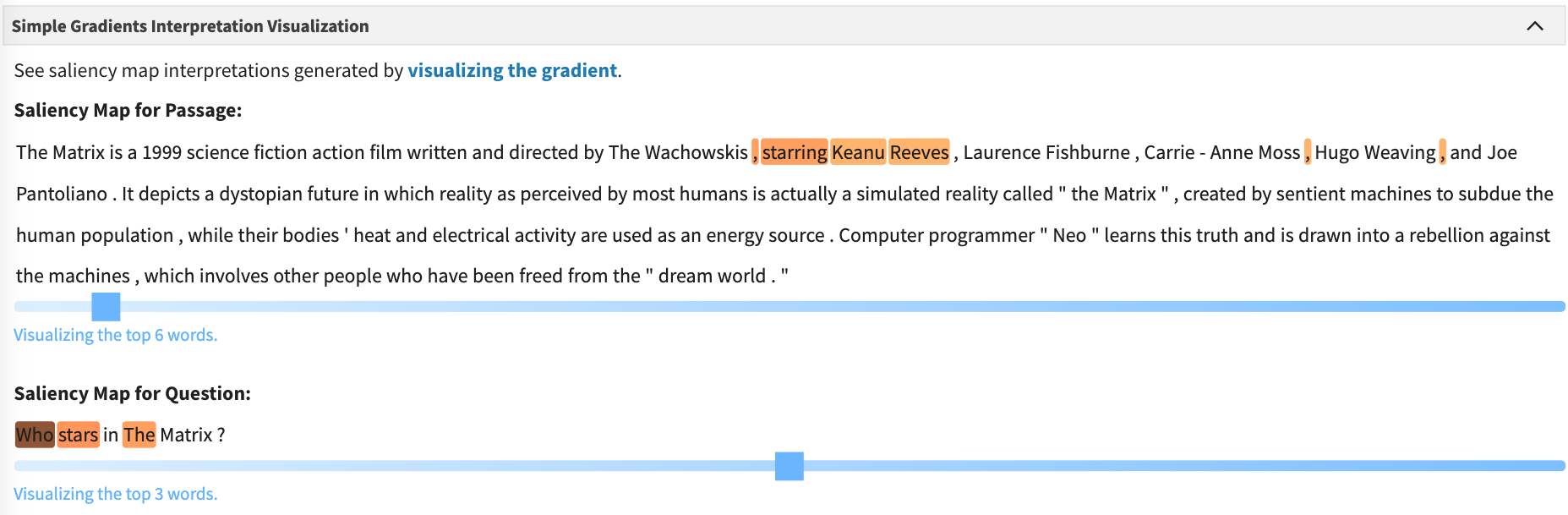
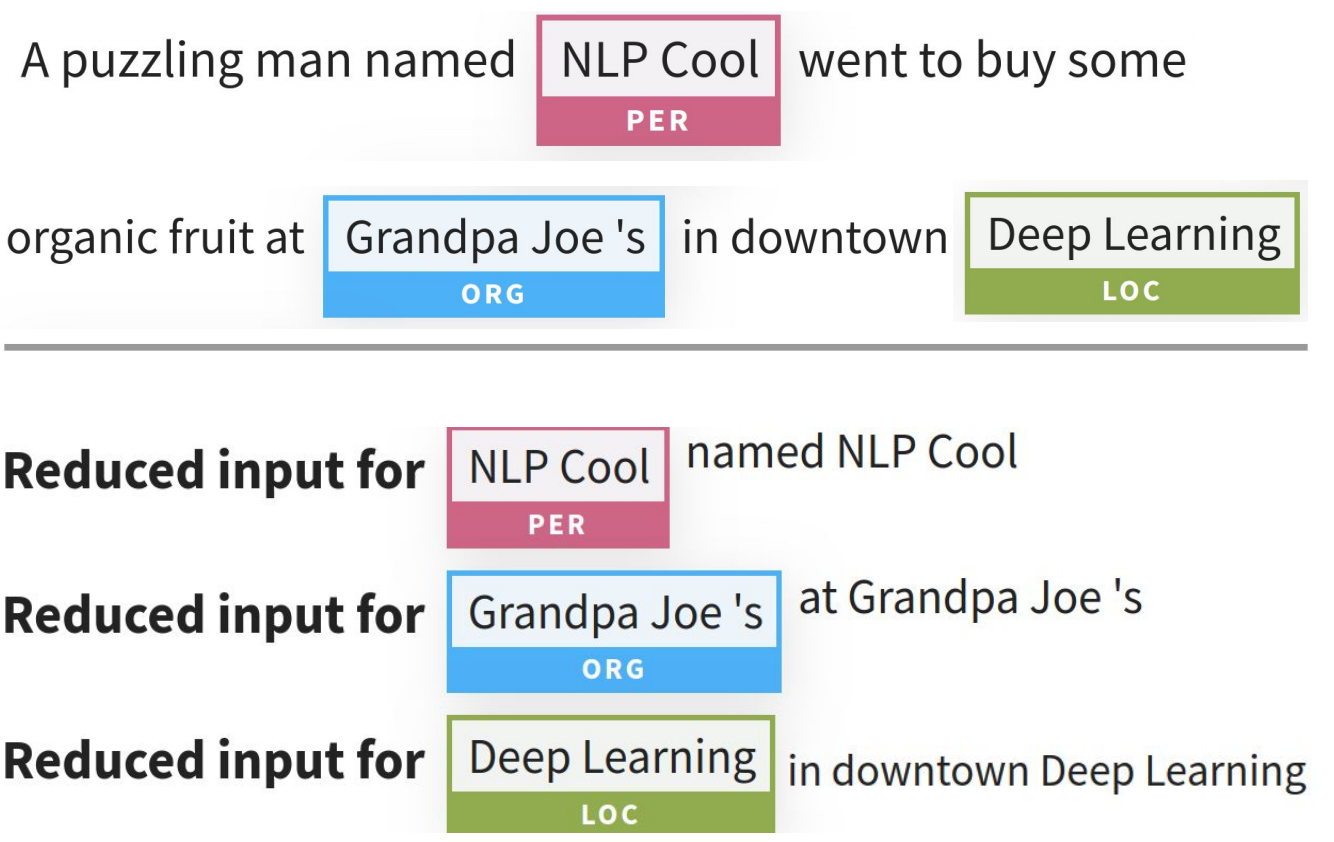
Citation:
@inproceedings{Wallace2019AllenNLP,
Author = {Eric Wallace and Jens Tuyls and Junlin Wang and Sanjay Subramanian
and Matt Gardner and Sameer Singh},
Booktitle = {Empirical Methods in Natural Language Processing},
Year = {2019},
Title = { {AllenNLP Interpret}: A Framework for Explaining Predictions of {NLP} Models}}





