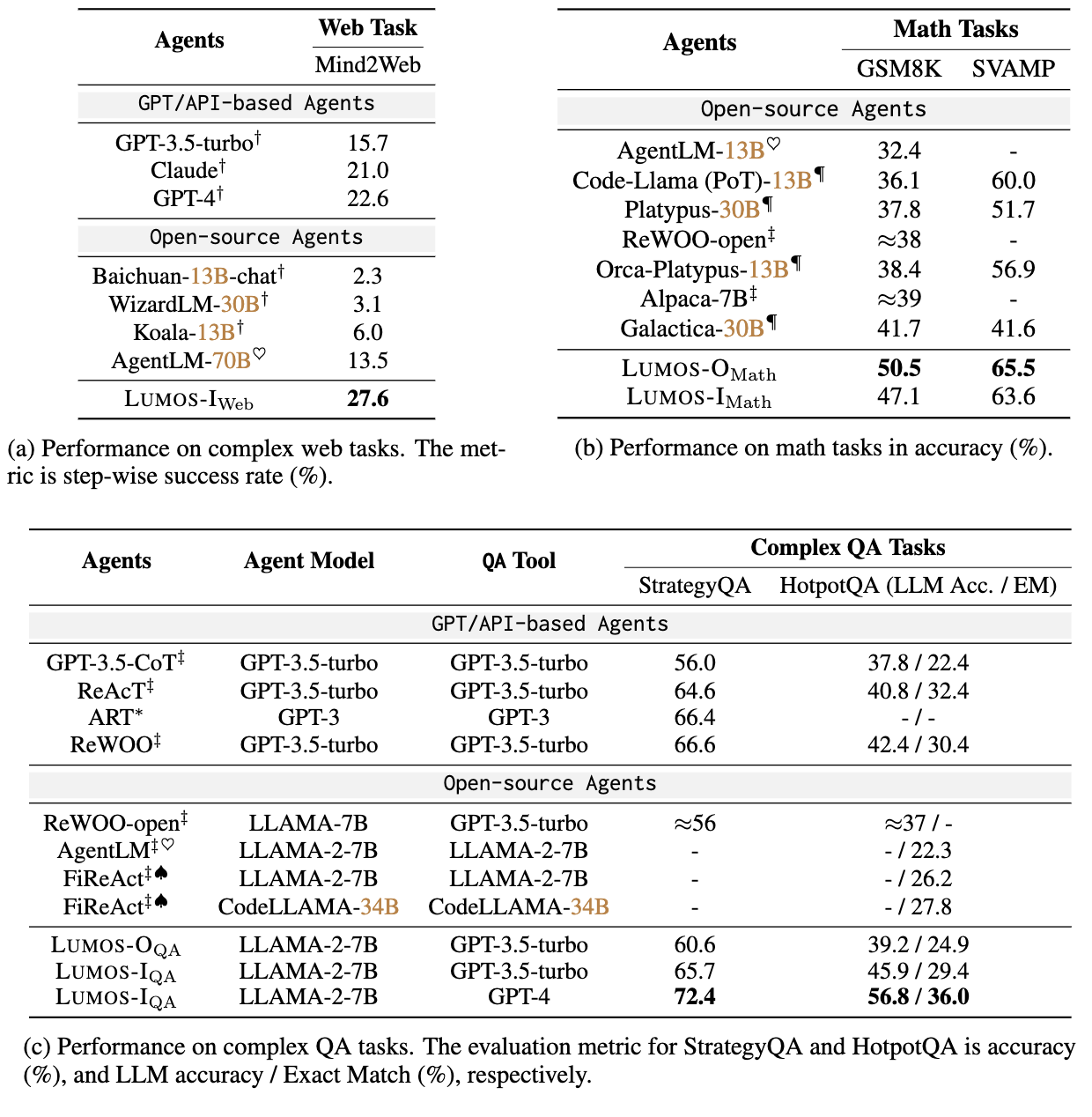
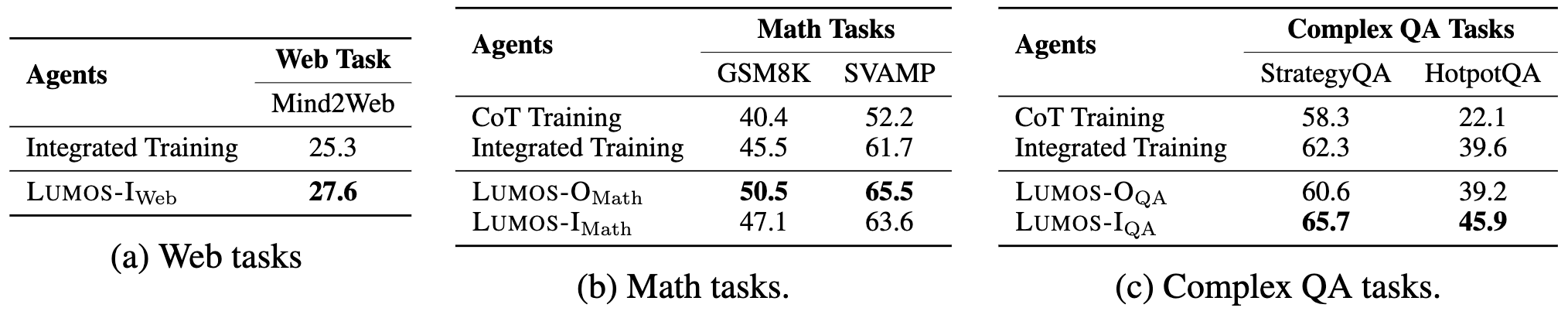
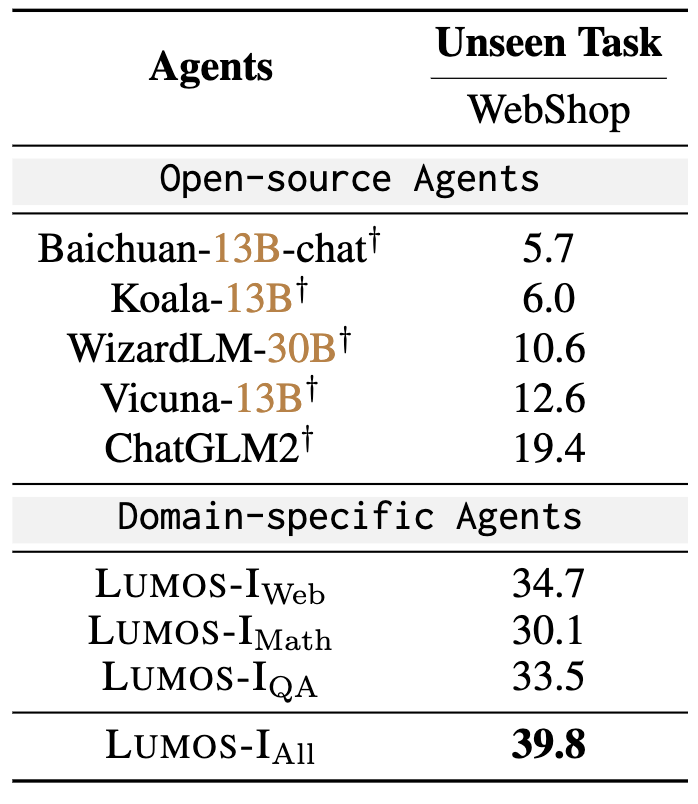
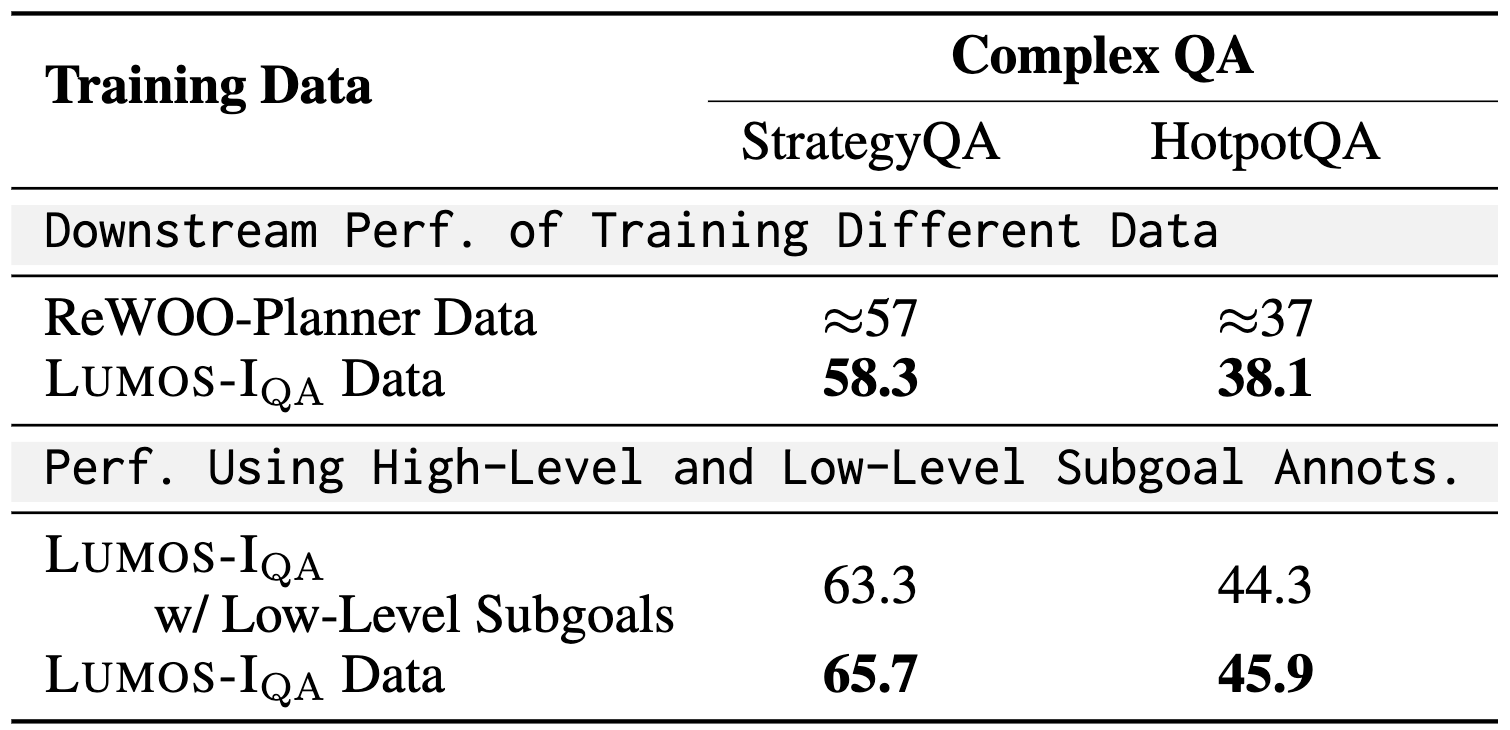
🪄 Lumos Architecture
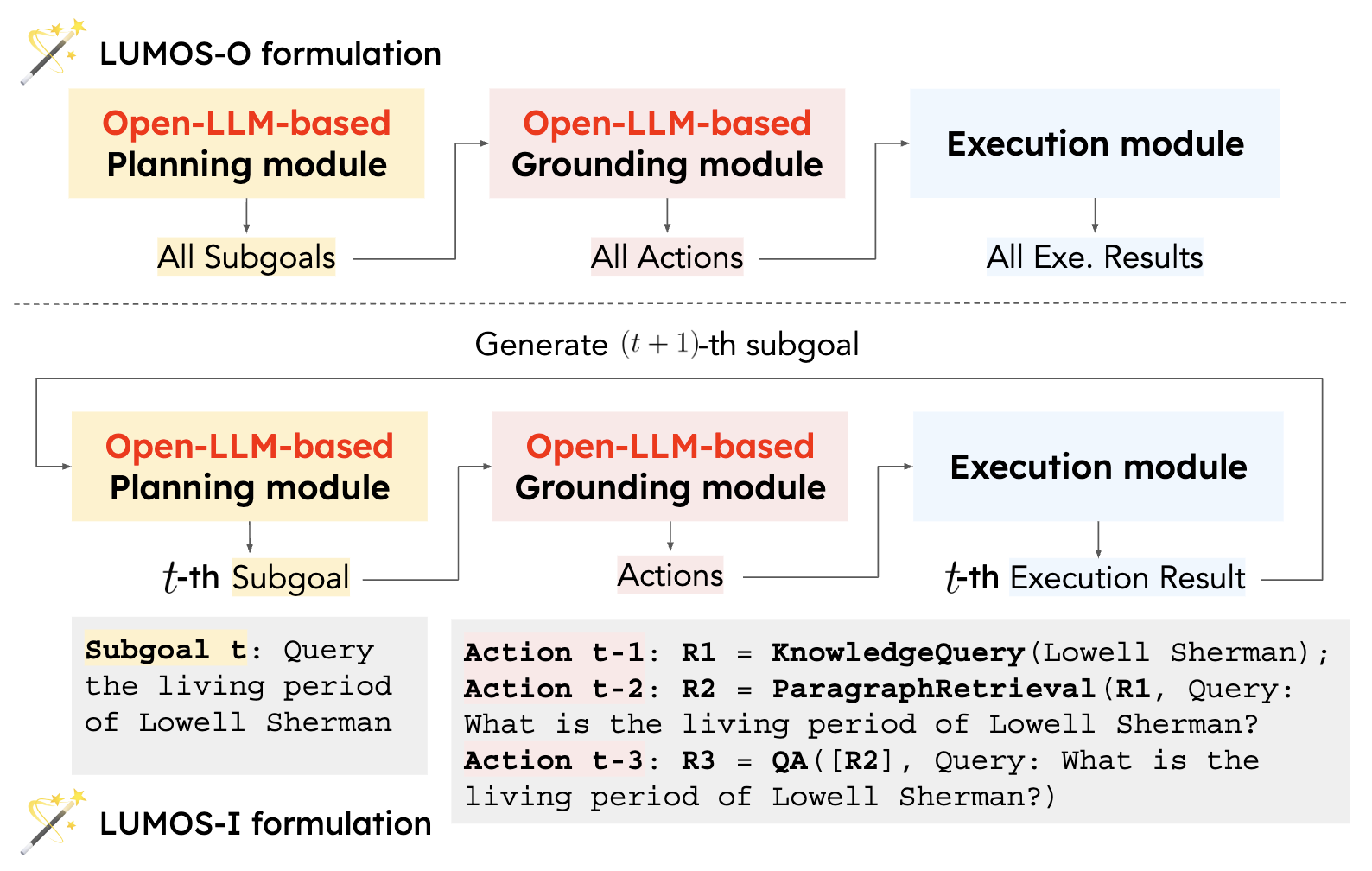
Lumos consists of following modules:
- Planning Module:
- Decompose a complex task into a series of high-level subgoals, which are written in natural language.
- Grounding Module:
- Convert the high-level subgoals produced by the planning module to low-level executable actions.
- Execution Module:
- Parse actions to a series of external tools including APIs, small neural models, and virtual simulators that interact with relevant tools and external environment.