Large language models (LLMs) have recently been used for sequential decision making in interactive environments. However, leveraging environment reward signals for continual LLM actor improvement is not straightforward. We propose Skill Set Optimization (SSO) for improving LLM actor performance through constructing and refining sets of transferable skills. SSO constructs skills by extracting common subtrajectories with high rewards and generating subgoals and instructions to represent each skill. These skills are provided to the LLM actor in-context to reinforce behaviors with high rewards. Then, SSO further refines the skill set by pruning skills that do not continue to result in high rewards. We evaluate our method in the classic videogame NetHack and the text environment ScienceWorld to demonstrate SSO's ability to optimize a set of skills and perform in-context policy improvement. SSO outperforms baselines by 40% in our custom NetHack task and outperforms the previous state-of-the-art in ScienceWorld by 35%.
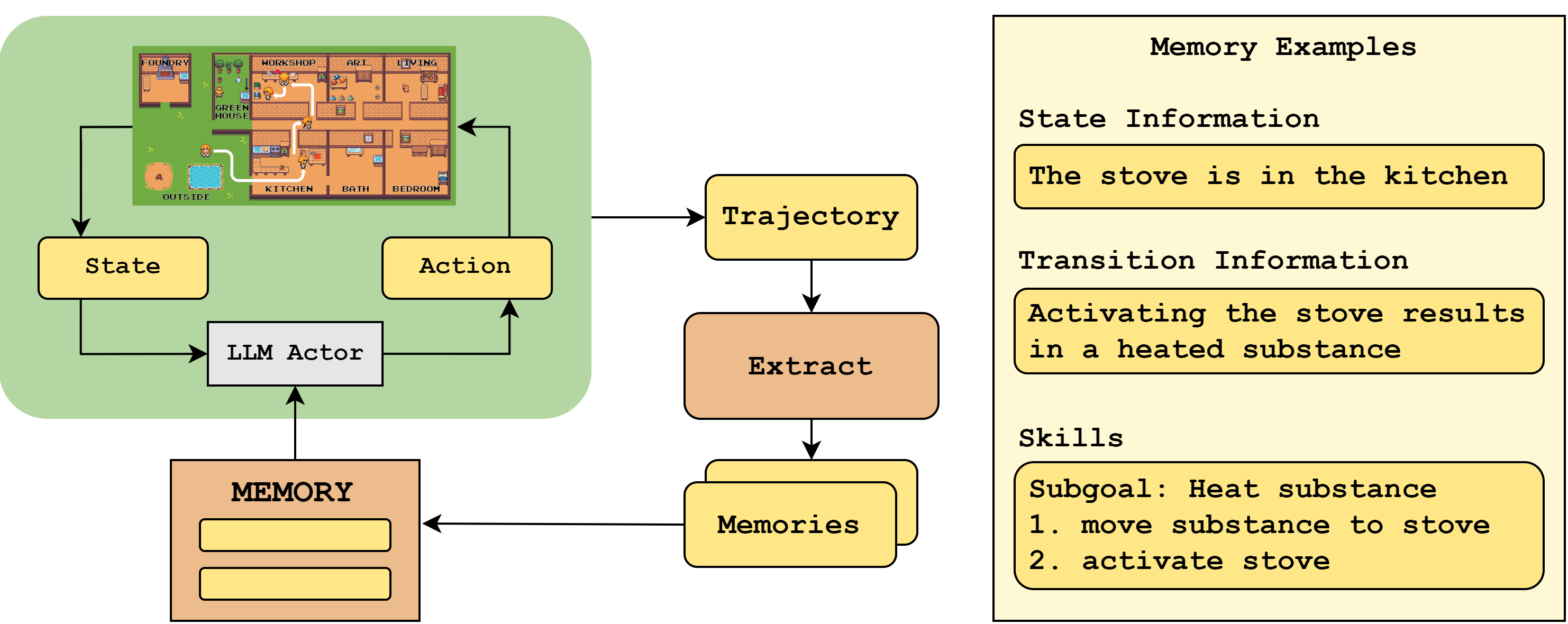
Like other continual learning methods*, SSO uses in-context "memories" with information about the task and environment to improve the LLM actor's policy. The memories that SSO generates are instructions for achieving subgoals we call skills. Unlike previous work, SSO continuously evaluates generated memories, creates memories that define modular subgoals, and facilitates memory retrieval.
* e.g. Voyager, ExpeL, and CLIN agents
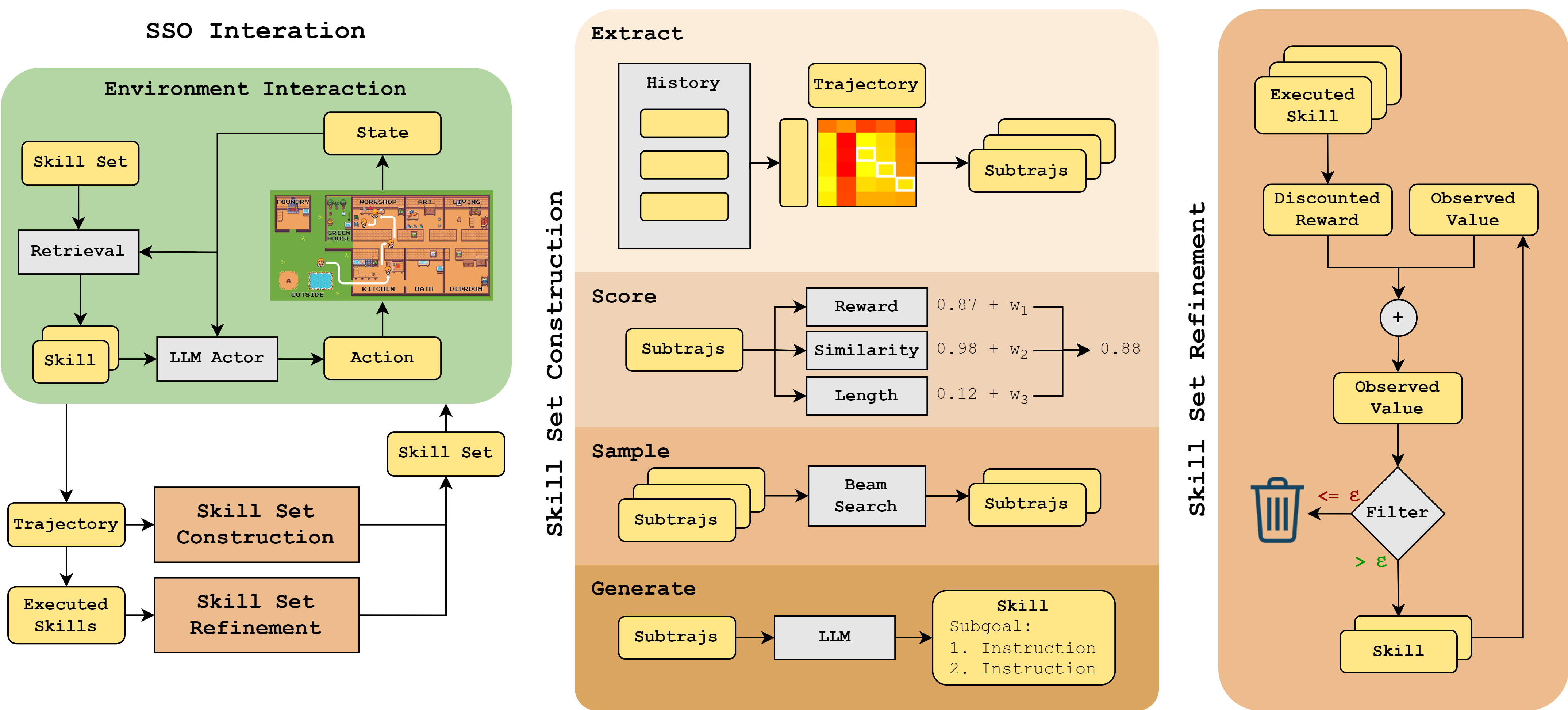
Each iteration of SSO includes:
To construct new skills, we extract potential subtrajectories, score them using discounted reward and similarity and length, sample an updated skill set using beam search, and generate subgoals and instructions for each new skill. We refine the constructed skill set by filtering skills that did not result in high rewards when used previous trajectories. Then, when providing skills in-context, we retrieve only the most relevant skills based on cosine similarity of skill initial states and the current environment state.
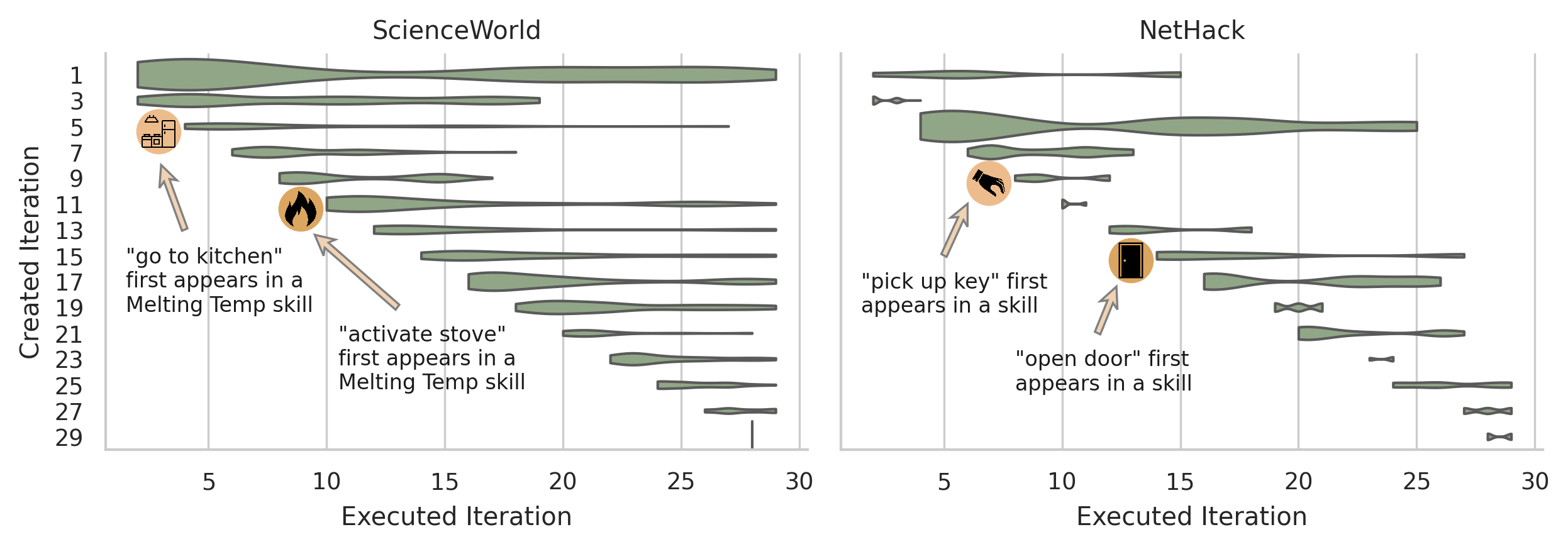
Each row of this plot shows all of the skills created in the cooresponding iteration and when they were executed. On both ScienceWorld and NetHack, SSO prunes most new skills after few iterations. The LLM actor uses more recent skills as it continues to improve at the task and learn new skills and improve old skills.
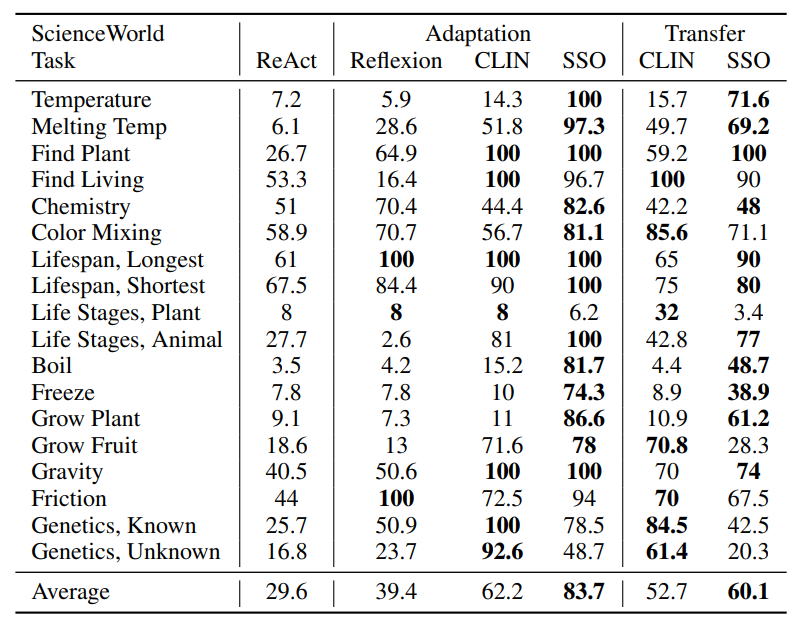
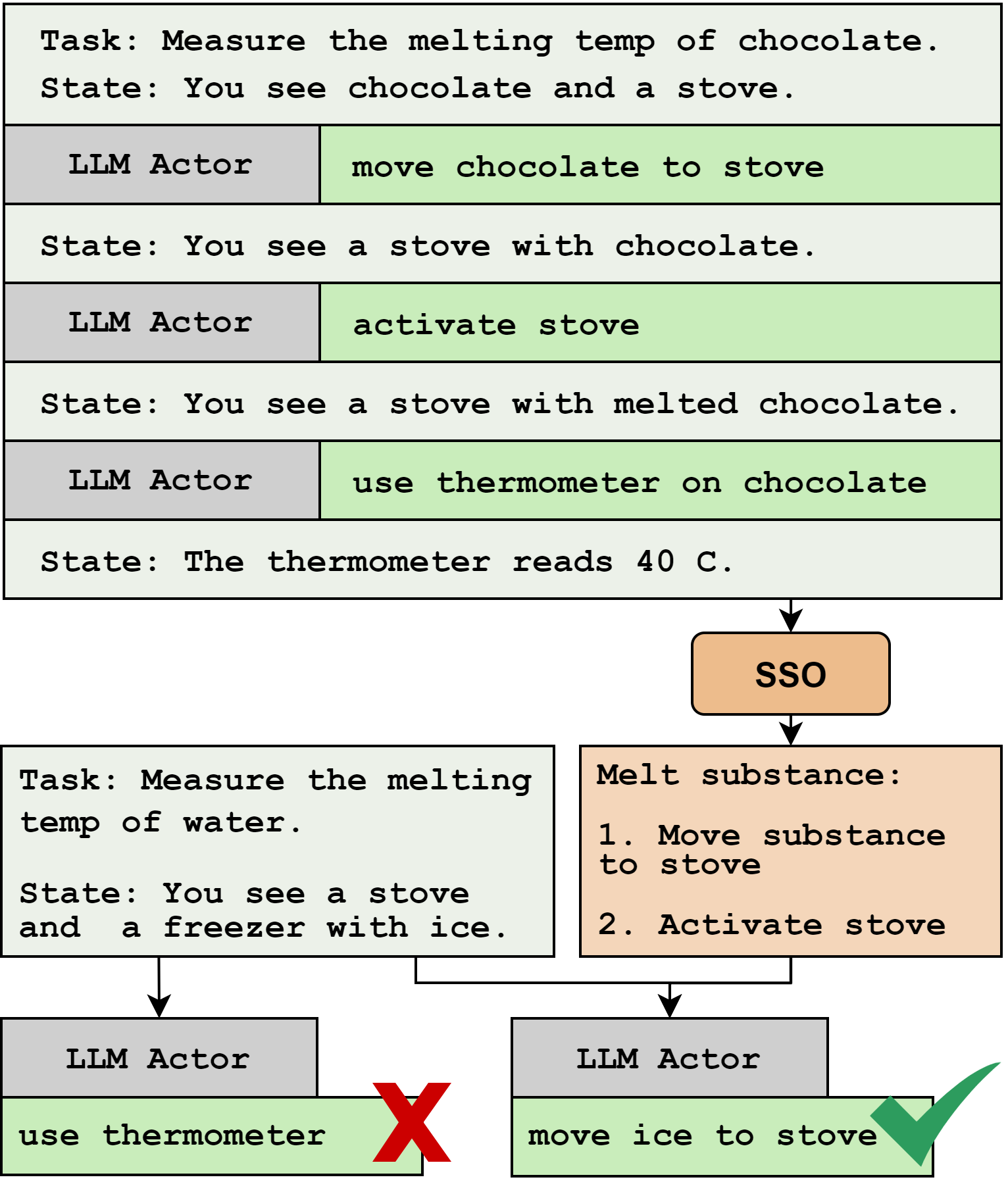
SSO outperforms previous state-of-the-art in ScienceWorld by 35% in task adaptation and 14% in task transfer. Learned and reinforced skills such as those listed below provide knowledge of subgoals that are transferable across tasks.
You move to the kitchen
|
The stove is turned on. on the stove is: a substance called liquid [substance]
|
@article{nottingham2024sso,
author = "Nottingham, Kolby and Majumder, Bodhisattwa Prasad and Dalvi Mishra, Bhavana and Singh, Sameer and Clark, Peter and Fox, Roy",
title = "Skill Set Optimization: Reinforcing Language Model Behavior via Transferable Skills",
journal = "arXiv",
year = "2024",
url = "https://arxiv.org/abs/2402.03244"
}