Supervised finetuning (SFT)
We support Supervised finetuning (SFT) on a variety of datasets.
Implemented Variants
- OLMo-core SFT (recommended): Uses OLMo-core's native training infrastructure. Most users should use this — it is more GPU-efficient and supports OLMo, Qwen, and other models. See
open_instruct/olmo_core_utils.pyfor the current list of supported models. finetune.pyis the legacy SFT implementation using DeepSpeed/Accelerate. Use this only if you need a model architecture not yet supported by OLMo-core.
olmo_core_finetune.py (OLMo-core)
The recommended SFT implementation uses OLMo-core's native training infrastructure (FSDP/HSDP). It supports torch.compile, padding-free training, budget-mode activation checkpointing, and W&B tracking. It is launched via build_image_and_launch.sh, just like DPO and GRPO.
Debug Scripts
| Script | Scale | Description | Launch |
|---|---|---|---|
scripts/train/debug/oc_sft.sh |
1 GPU, Beaker | Single-GPU test with Qwen3-0.6B. | ./scripts/train/build_image_and_launch.sh scripts/train/debug/oc_sft.sh |
scripts/train/debug/oc_sft_multinode.sh |
2 nodes (16 GPUs), Beaker | Multi-node test with Qwen3-0.6B. Exercises HSDP sharding. | ./scripts/train/build_image_and_launch.sh scripts/train/debug/oc_sft_multinode.sh |
Key Flags
| Group | Flag | Description | Default |
|---|---|---|---|
| Experiment | --exp_name |
Name of this experiment | "sft" |
--run_name |
Unique run name (for W&B) | None |
|
--seed |
Random seed for initialization and dataset shuffling | 42 |
|
| Model | --model_name_or_path |
Model checkpoint for weight initialization | — |
--config_name |
Pretrained config name or path if different from model | None |
|
--attn_implementation |
Attention backend: flash-2, flash-3, torch (auto-detected if unset) |
None |
|
| Training | --learning_rate |
Initial learning rate | 8e-5 |
--num_epochs |
Total number of training epochs | 3 |
|
--max_train_steps |
If set, overrides num_epochs |
None |
|
--per_device_train_batch_size |
Batch size per GPU | 8 |
|
--gradient_accumulation_steps |
Gradient accumulation steps | 1 |
|
--max_seq_length |
Maximum sequence length after tokenization | 4096 |
|
--warmup_ratio |
Linear warmup fraction of total steps | 0.03 |
|
--weight_decay |
Weight decay for AdamW | 0.0 |
|
--max_grad_norm |
Maximum gradient norm for clipping (-1 = no clipping) | -1 |
|
--compile_model |
Apply torch.compile to model blocks |
True |
|
--activation_memory_budget |
Activation checkpointing budget (0.0–1.0); values < 1.0 enable budget-mode checkpointing | 1.0 |
|
| Data | --mixer_list |
List of datasets (local or HF) to sample from | allenai/tulu-3-sft-olmo-2-mixture |
--mixer_list_splits |
Dataset splits for training | ["train"] |
|
--transform_fn |
List of transform functions to apply to the dataset | sft_tulu_tokenize_and_truncate_v1, sft_tulu_filter_v1 |
|
--cache_dataset_only |
Exit after caching the dataset | False |
|
--skip_cache |
Skip dataset caching | False |
|
| Checkpointing | --output_dir |
Output directory for checkpoints | output/ |
--checkpointing_steps |
Save a persistent checkpoint every N steps | 500 |
|
--ephemeral_save_interval |
Temporary checkpoint cadence (must be ≤ checkpointing_steps) |
500 |
|
| Logging | --with_tracking |
Enable Weights and Biases tracking | False |
--wandb_project |
W&B project name | "open_instruct_internal" |
|
--wandb_entity |
W&B entity (team) | None |
|
--logging_steps |
Log metrics every N steps | 1 |
Parallelism
The script automatically selects the data-parallel strategy based on the number of nodes:
- Single node: FSDP (Fully Sharded Data Parallel)
- Multiple nodes: HSDP (Hybrid Sharded Data Parallel) — shards within each node, replicates across nodes
See OLMo-core Sharding and Parallelism for more details on parallelism configuration.
finetune.py (Legacy)
This implementation has the following key features:
- Auto save the trained checkpoint to HuggingFace Hub
- Supports LigerKernel for optimized training with fused operations
Debug Scripts
| Script | Scale | Launch |
|---|---|---|
scripts/train/debug/finetune.sh |
1 GPU, local | bash scripts/train/debug/finetune.sh |
scripts/train/debug/sft_integration_test.sh |
1 GPU, Beaker | ./scripts/train/build_image_and_launch.sh scripts/train/debug/sft_integration_test.sh |
scripts/train/debug/sft_multinode_test.sh |
2 nodes, Beaker | ./scripts/train/build_image_and_launch.sh scripts/train/debug/sft_multinode_test.sh |
Key Flags
| Group | Flag | Description | Default |
|---|---|---|---|
| Model | --model_name_or_path |
Model checkpoint for weight initialization | — |
--use_liger_kernel |
Use LigerKernel for optimized training | False |
|
| Training | --learning_rate |
Initial learning rate | 2e-5 |
--num_train_epochs |
Total number of training epochs | 2 |
|
--per_device_train_batch_size |
Batch size per GPU | 8 |
|
--gradient_accumulation_steps |
Gradient accumulation steps | 1 |
|
--max_seq_length |
Maximum sequence length after tokenization | — | |
--warmup_ratio |
Linear warmup fraction of total steps | 0.03 |
|
--lr_scheduler_type |
LR scheduler: linear, cosine, etc. |
linear |
|
--gradient_checkpointing |
Use gradient checkpointing (saves memory) | False |
|
--seed |
Random seed | 42 |
|
| Data | --dataset_mixer_list |
List of datasets (local or HF) to sample from | — |
--dataset_mixer_list_splits |
Dataset splits for training | ["train"] |
|
--chat_template_name |
Chat template to use | None |
|
--packing |
Use packing/padding-free collation | False |
|
| Parallelism | --sequence_parallel_size |
Ulysses sequence parallelism degree | 1 |
| LoRA | --use_lora |
Use LoRA for parameter-efficient training | False |
--lora_rank |
Rank of LoRA | 64 |
|
--lora_alpha |
Alpha parameter of LoRA | 16 |
|
| Checkpointing | --output_dir |
Output directory for checkpoints | output/ |
--checkpointing_steps |
Save every N steps or epoch |
— | |
--resume_from_checkpoint |
Resume from checkpoint folder | None |
|
| Logging | --with_tracking |
Track experiment with Weights and Biases | False |
--logging_steps |
Log training loss every N steps | — |
Reproduce allenai/Llama-3.1-Tulu-3-8B-SFT (8 Nodes)
You can reproduce our allenai/Llama-3.1-Tulu-3-8B-SFT model by running the following command:
bash scripts/train/tulu3/finetune_8b.sh
Info
If you are an external user, mason.py will print out the actual command being executed on our internal server, so you can modify the command as needed.

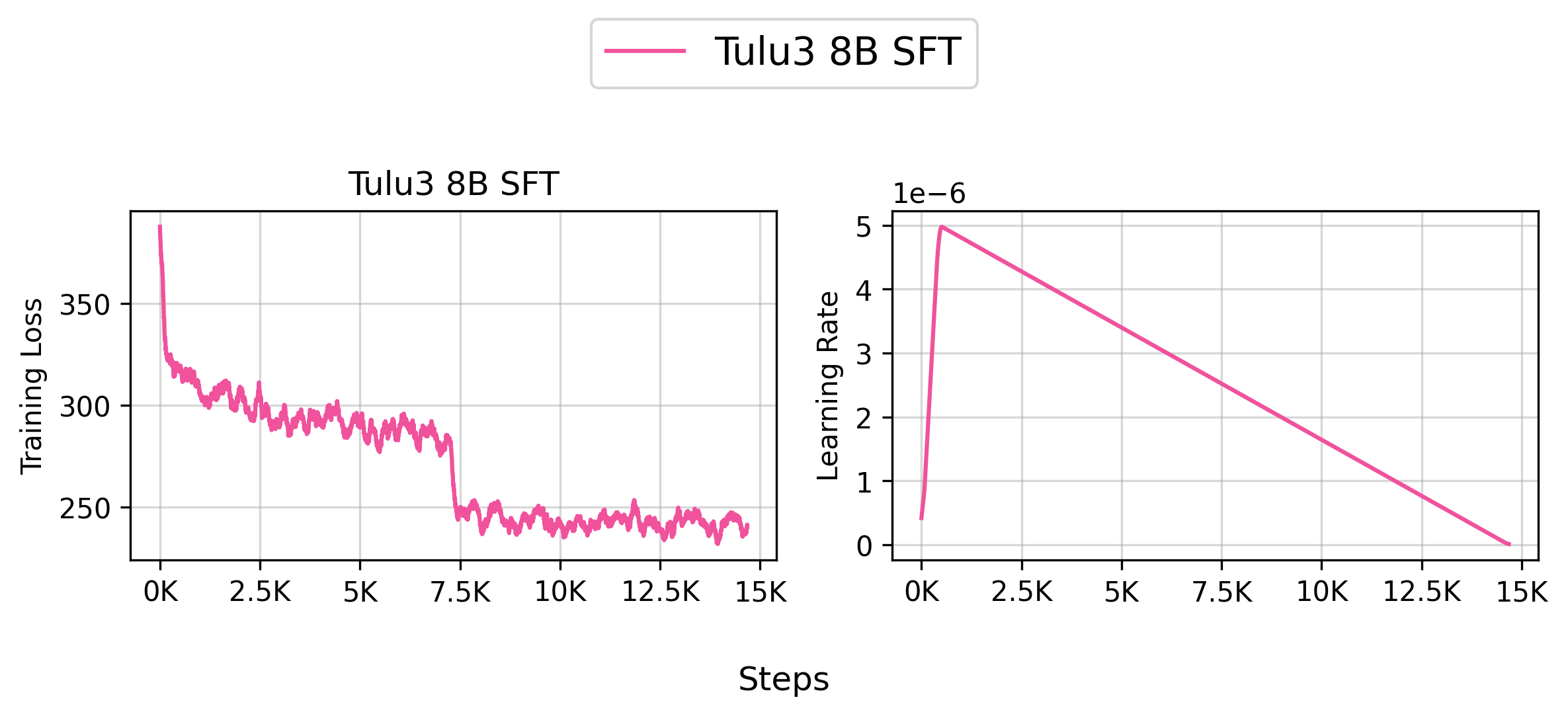
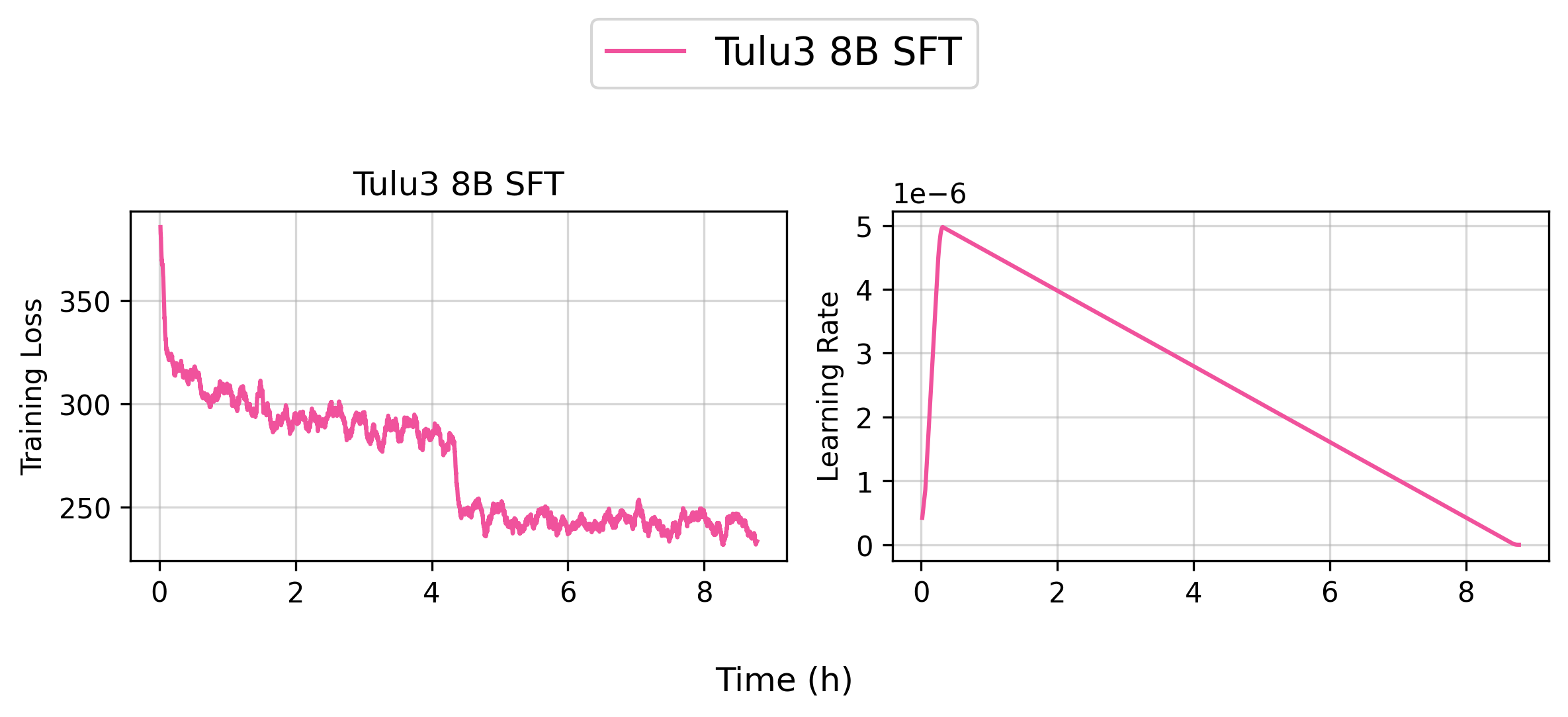
👉 Tracked WandB Experiments (Click to expand)
Info
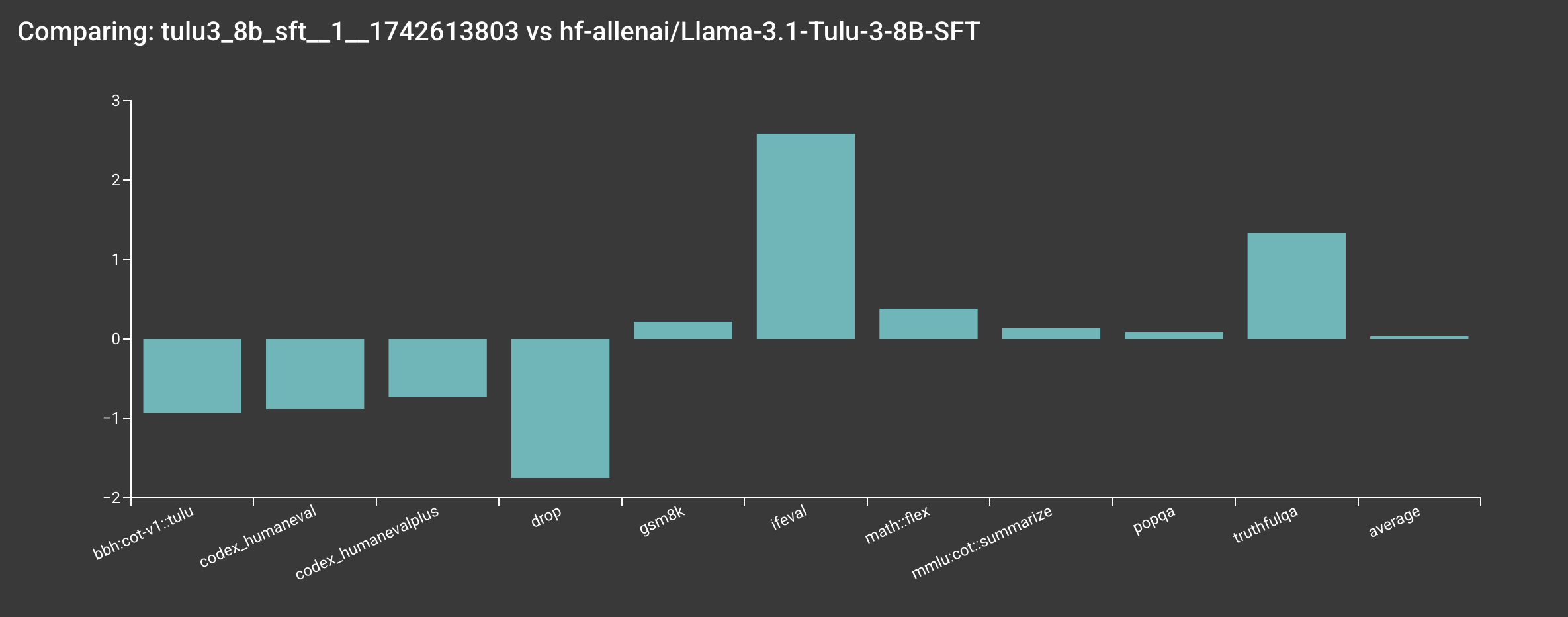
Based on our internal evaluation, the SFT model is roughly on par with the original allenai/Llama-3.1-Tulu-3-8B model, though there are some slight differences. Note that your results may vary slightly due to the random seeds used in the training.
Info
We haven't quite figured out how to make our internal evaluation toolchains more open yet. Stay tuned!
Reproduce allenai/OLMo-2-1124-7B-SFT (8 Nodes)
You can reproduce our allenai/OLMo-2-1124-7B-SFT model by running the following command:
bash scripts/train/olmo2/finetune_7b.sh
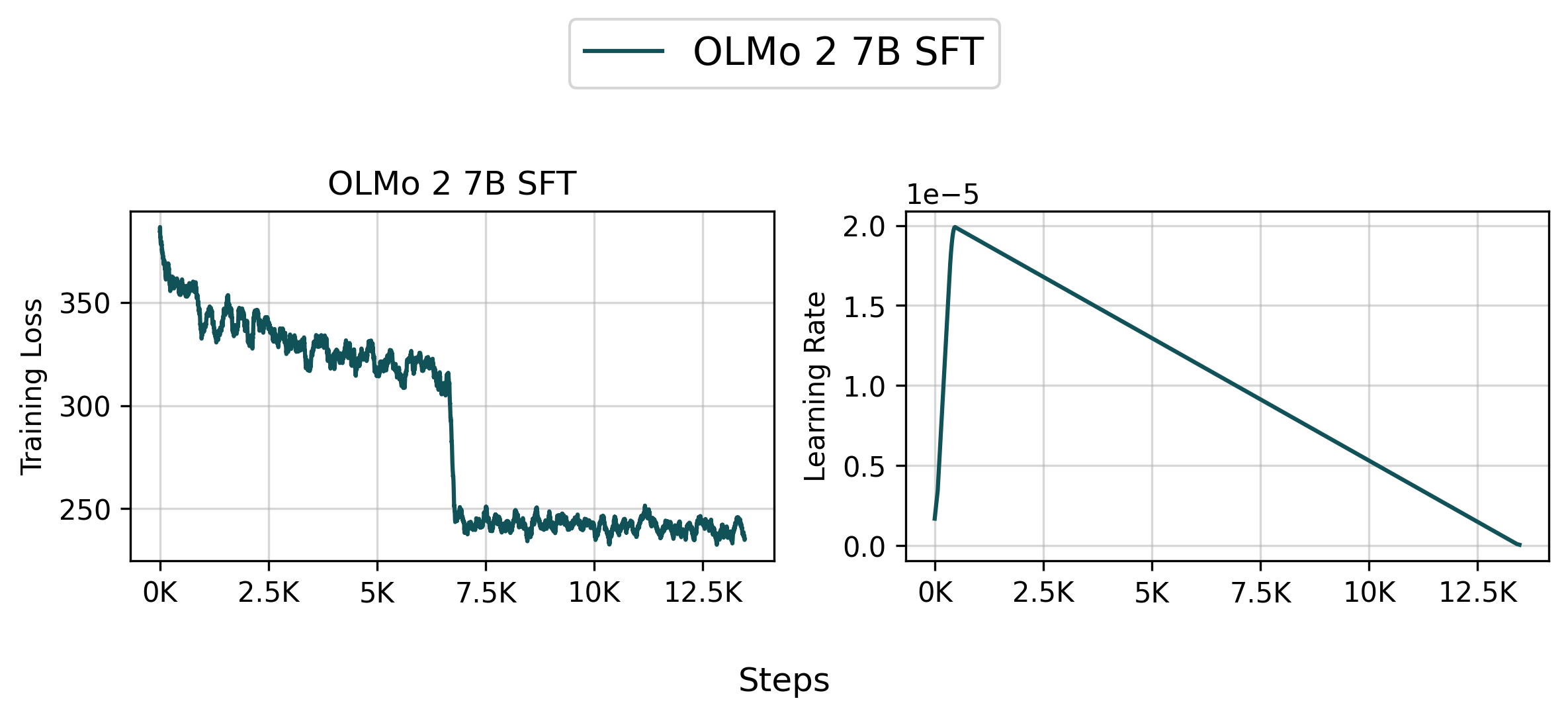
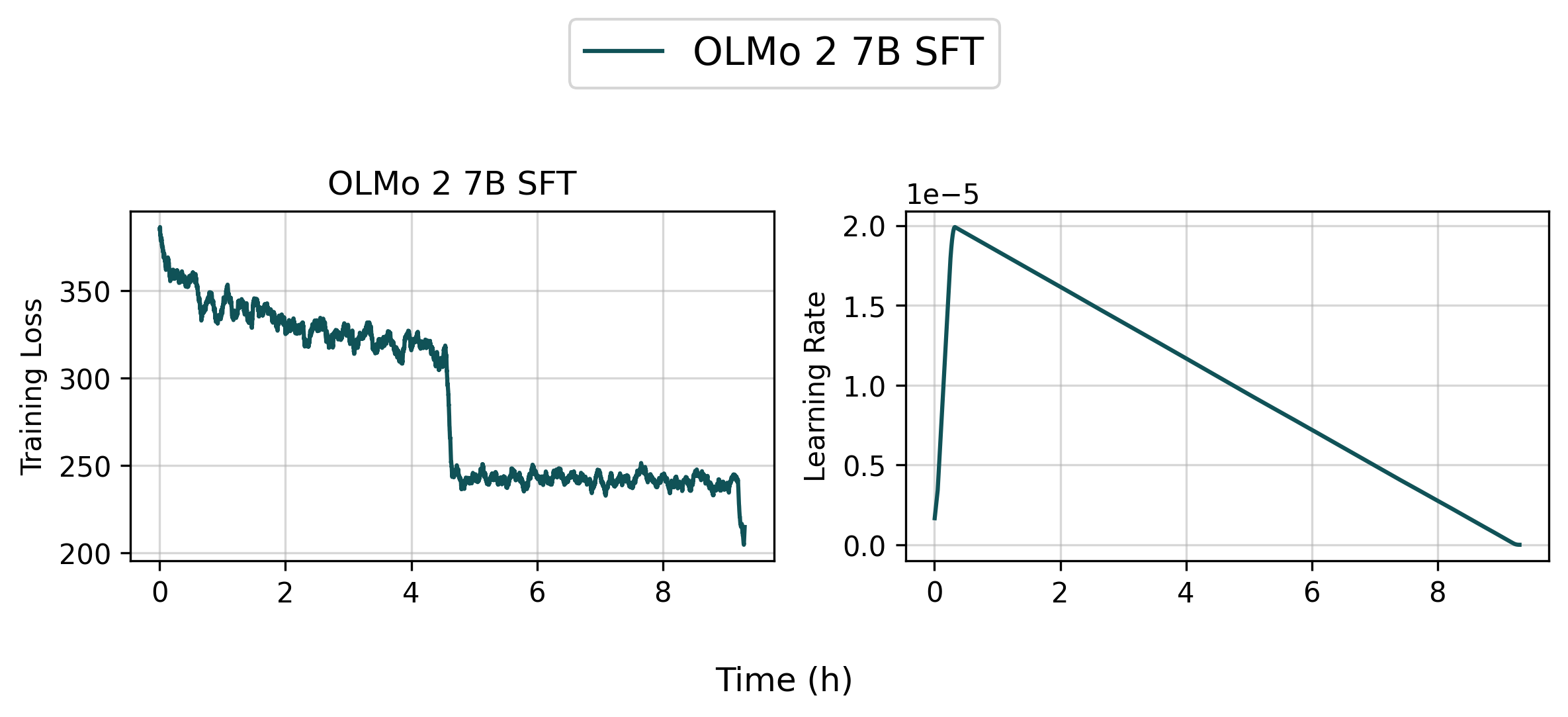
👉 Tracked WandB Experiments (Click to expand)
Info
Based on our internal evaluation, the SFT model is roughly on par with the original allenai/OLMo-2-1124-7B model, though there are some slight differences. Note that your results may vary slightly due to the random seeds used in the training.
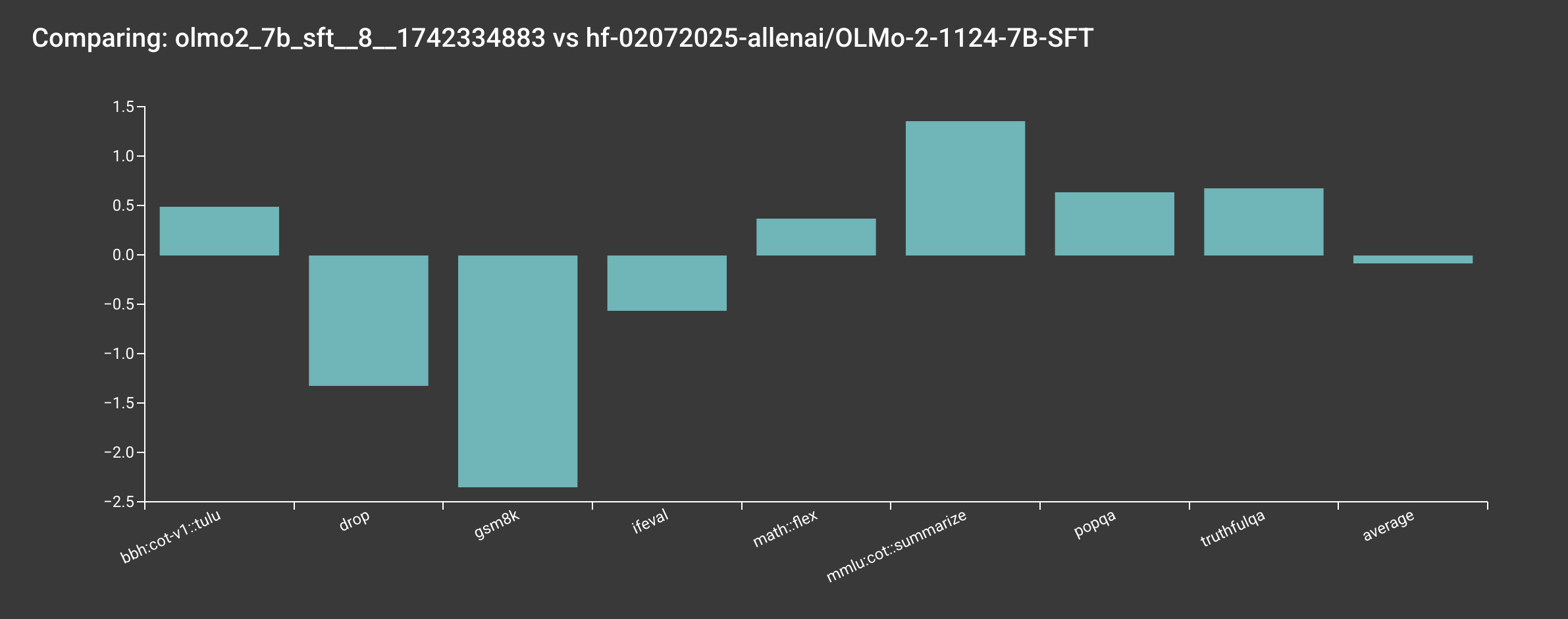
Info
We haven't quite figured out how to make our internal evaluation toolchains more open yet. Stay tuned!
Reproduce allenai/OLMo-2-1124-13B-SFT (8 Nodes)
You can reproduce our allenai/OLMo-2-1124-13B-SFT model by running the following command:
bash scripts/train/olmo2/finetune_13b.sh
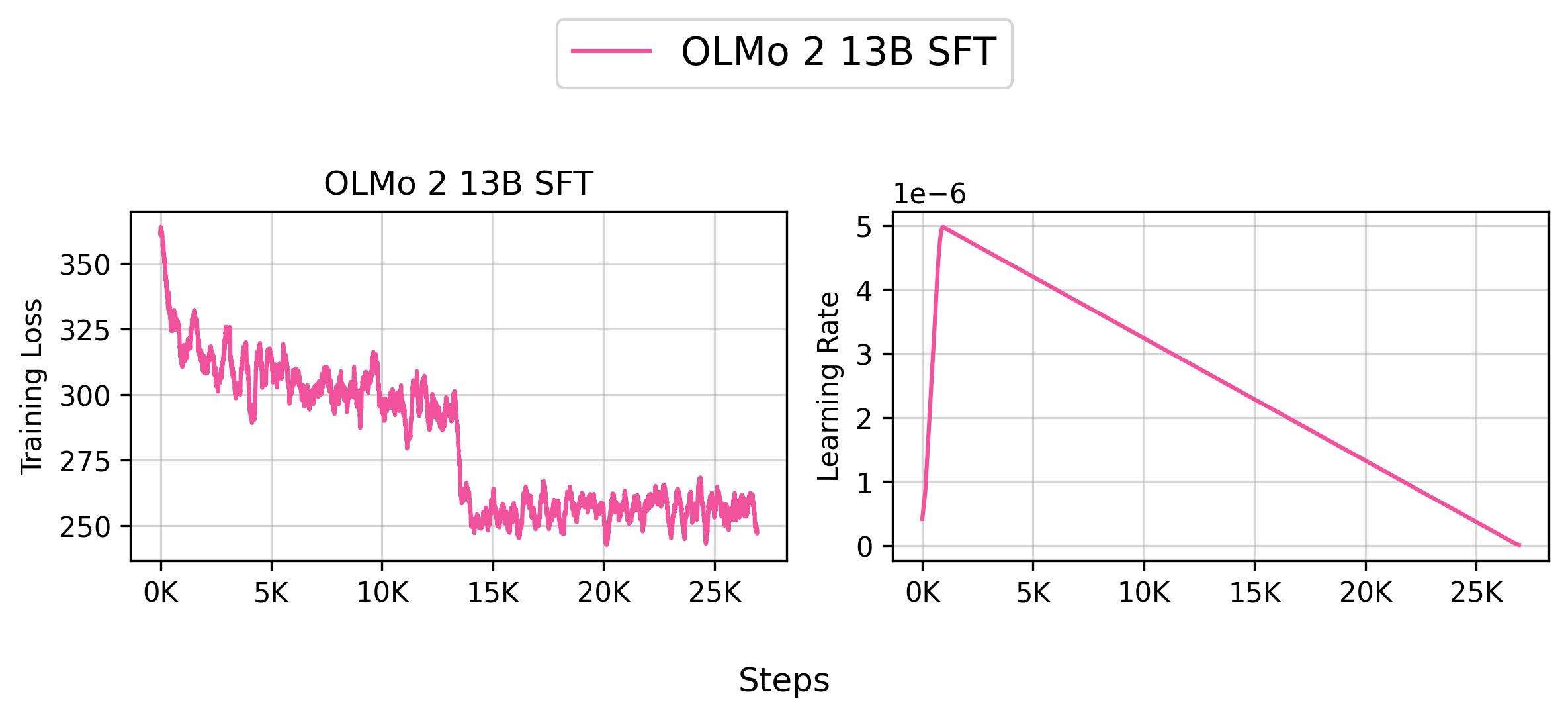
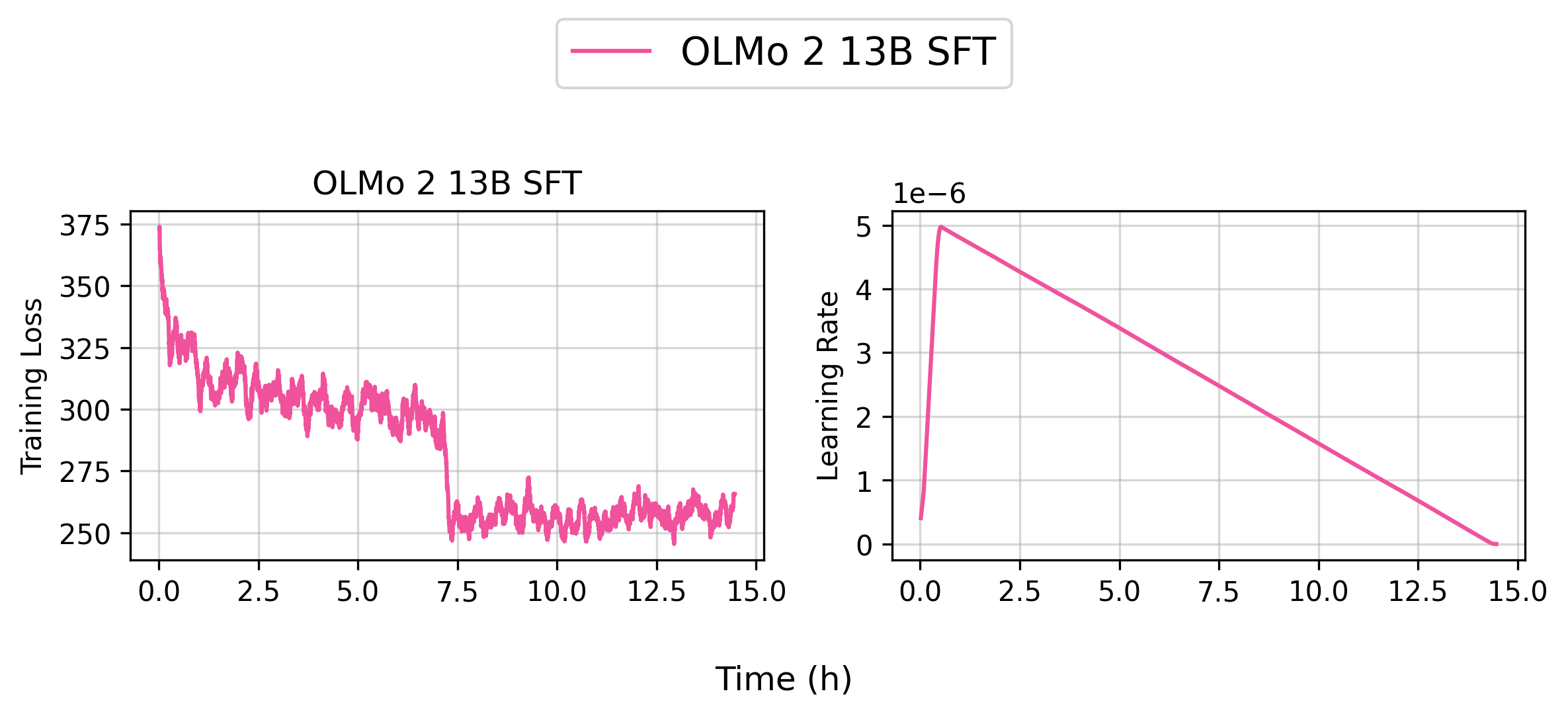
👉 Tracked WandB Experiments (Click to expand)
Info
Based on our internal evaluation, the SFT model is roughly on par with the original allenai/OLMo-2-1124-7B model, though there are some slight differences. Note that your results may vary slightly due to the random seeds used in the training.

Info
We haven't quite figured out how to make our internal evaluation toolchains more open yet. Stay tuned!
Reproduce allenai/OLMo-2-1124-32B-SFT (8 Nodes)
You can reproduce our allenai/OLMo-2-1124-32B-SFT model by running the following command:
bash scripts/train/olmo2/finetune_32b.sh
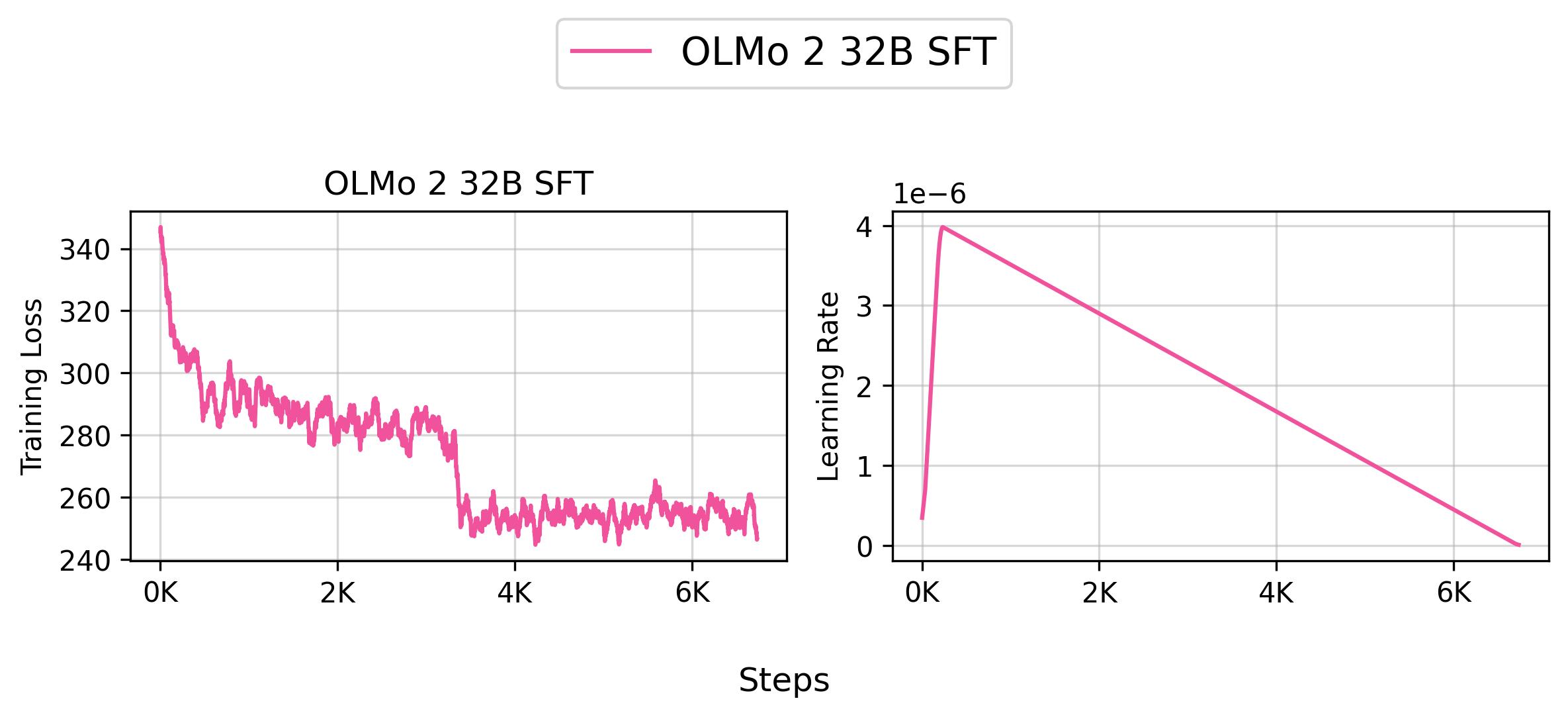
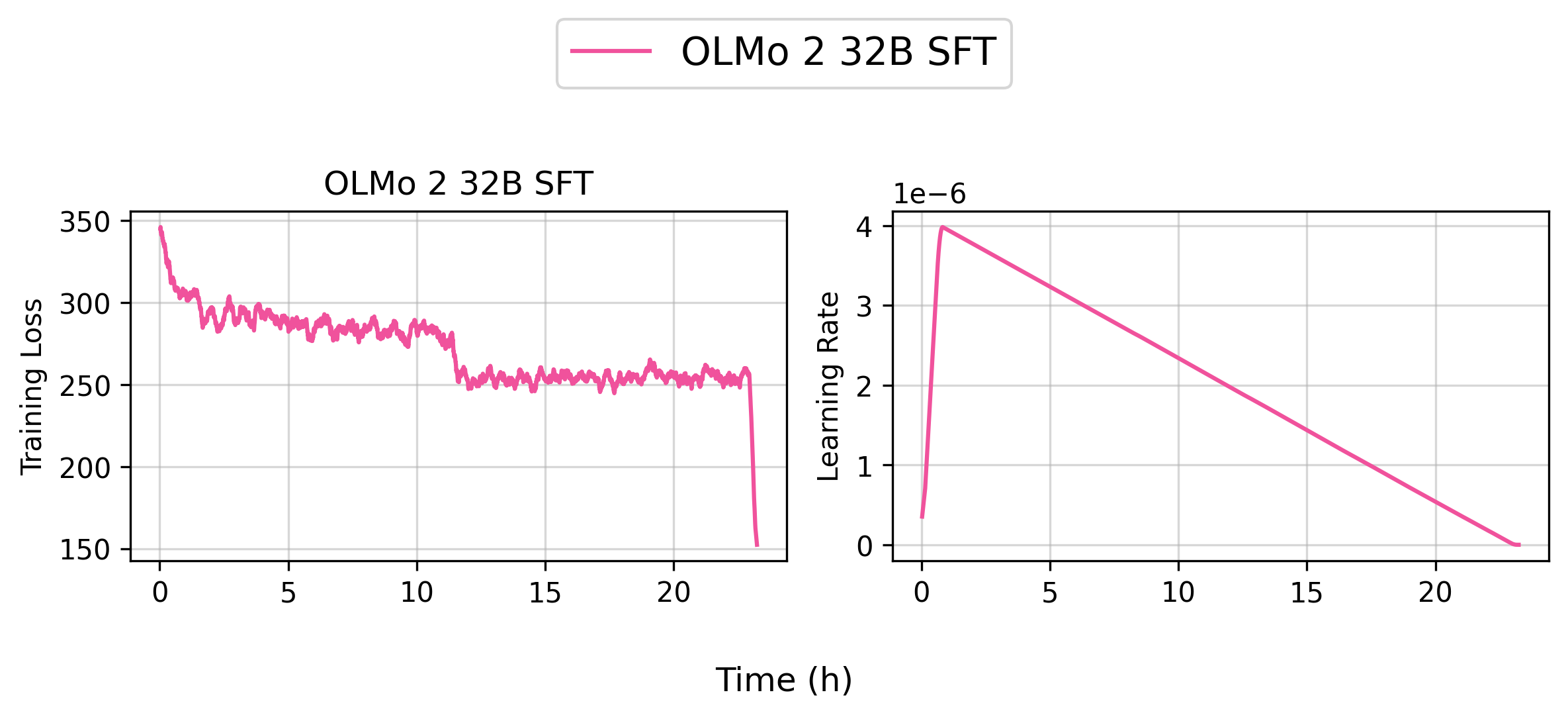
👉 Tracked WandB Experiments (Click to expand)
Info
Based on our internal evaluation, the SFT model is roughly on par with the original allenai/OLMo-2-1124-7B model, though there are some slight differences. Note that your results may vary slightly due to the random seeds used in the training.
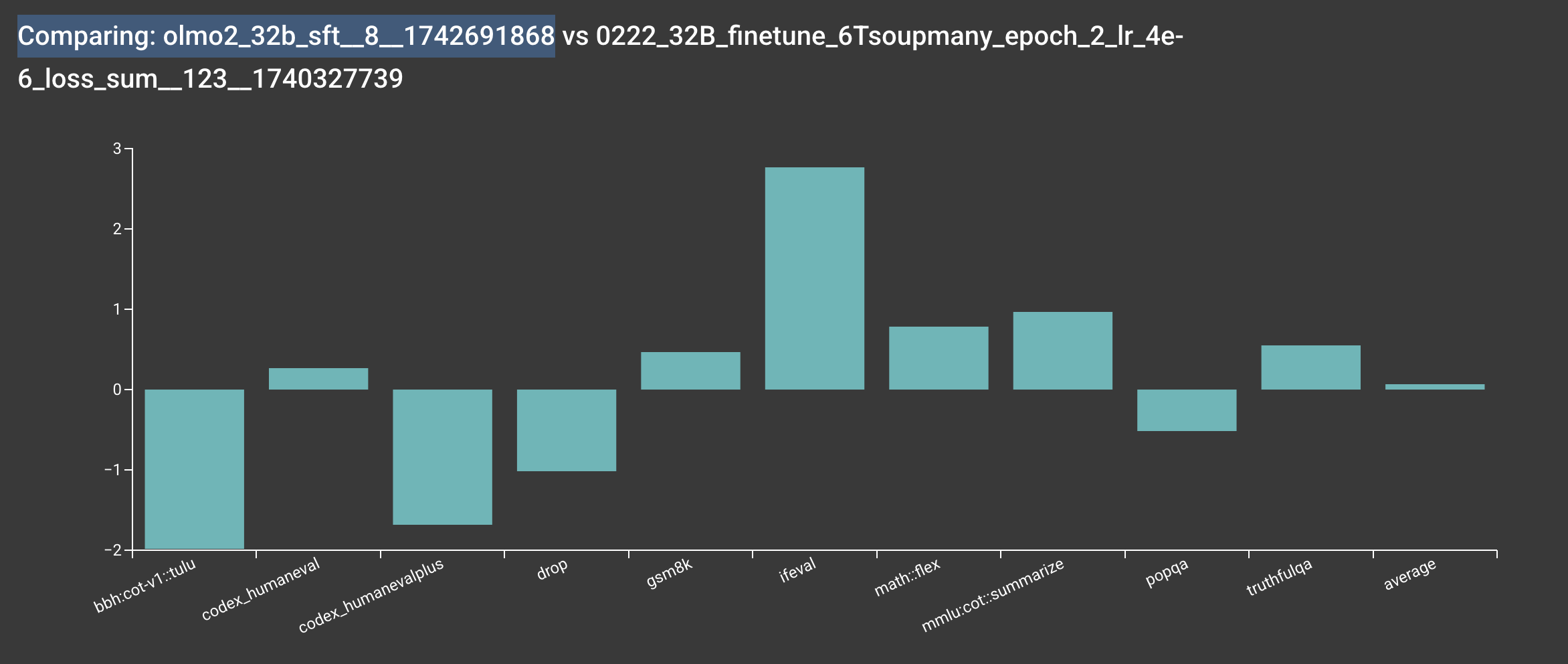
Info
We haven't quite figured out how to make our internal evaluation toolchains more open yet. Stay tuned!
Training Metrics
During training, the following metrics are logged:
learning_rate: The current learning rate from the learning rate schedulertrain_loss: The average training loss over the logged stepstotal_tokens: Total number of tokens processed (excluding padding)per_device_tps: Tokens per second processed per device (excluding padding)total_tokens_including_padding: Total number of tokens including padding tokensper_device_tps_including_padding: Tokens per second processed per device (including padding)
The metrics are logged every logging_steps steps (if specified) and provide insights into:
- Training progress (loss, learning rate)
- Training efficiency (tokens per second)
- Resource utilization (padding vs non-padding tokens)
Acknowledgements
We would like to thank the following projects for general infrastructure: