Introduction
❓ Superficial alignment analysis: Alignment tuning (SFT+RLHF) has become the de facto standard practice for enabling base LLMs to serve as open-domain AI assistants such as ChatGPT.
On the other hand, a recent study, LIMA, shows that using only 1K examples for SFT can achieve significant alignment performance as well, suggesting that the effect of alignment tuning might be superficial.
This raises questions about how exactly the alignment tuning transforms a base LLM.
🔍 Token Distribution Shifts:
To this end, we analyze the effect of alignment by examining the token distribution shift
between a base LLM and its aligned counterpart.
Our findings indicate that a pair of base and aligned LLMs usually perform nearly identically when decoding top tokens on the majority of token positions.
Most distribution shifts occur with stylistic tokens (e.g., discourse markers, safety disclaimers). This strongly confirms that alignment tuning primarily learns to adopt the language style of AI assistants in large part, and that the knowledge applied for answering user queries predominantly arises from pre-training.
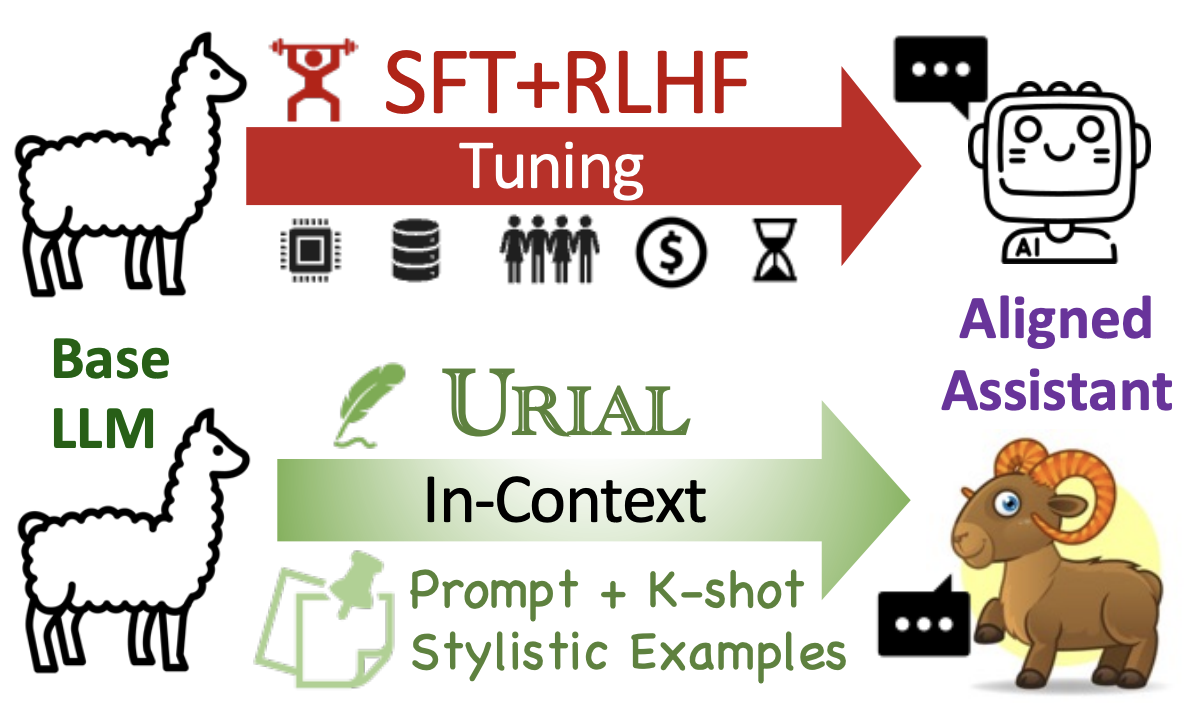
🐑 URIAL Align: We rethink the alignment of LLMs by posing the research question:
how effectively can we align base LLMs without SFT or RLHF?
To address this, we introduce a simple, tuning-free alignment method, URIAL (Untuned LLMs with Restyled In-context ALignment).
URIAL achieves effective alignment purely through in-context learning (ICL), requiring as few as three constant stylistic examples and a system prompt.

⚖️ Just-Eval-Instruct: We conduct a fine-grained and interpretable evaluation on a diverse set of examples, named JUST-EVAL-INSTRUCT, which demonstrates that URIAL can match or even surpass the performance of LLMs aligned with SFT or SFT+RLHF.
Our empirical results show that the gap between tuning-free and tuning-based alignment methods can be significantly reduced through strategic prompting and ICL.


Key Findings from Token Distribution Shifts:
- Alignment affects only a very small fraction of tokens. The base and aligned LLMs behave the same in decoding on most positions, where they share the same top-ranked tokens.
- Alignment mainly concerns stylistic tokens, such as discourse markers, transitional words, and safety disclaimers, which only take about 5-8% of the positions.
- Alignment is more critical for earlier tokens. For most positions, the aligned model's top-ranked token is within the top 5 tokens ranked by the base model.
- Base LLMs have already acquired adequate knowledge to follow instructions. They behave very similarly to aligned LLMs when given an appropriate context as a prefix.
URIAL's contributions
- URIAL is a strong baseline method for aligning base LLMs without tuning. It is extremely simple to implement and perfectly reproducible, thus facilitating the development and evaluation of future tuning-free and tuning-based alignment methods.
- URIAL can align extremely large LMs with minimal effort. Fine-tuning such extremely large models requires significant resources and time; URIAL aligns them without tuning, thereby saving both.
- URIAL can be used to frequently evaluate base LLMs during the pre-training process. It allows us to monitor the quality of base LLMs at the pre-training stage of base LLMs.
- URIAL enables fair comparison of different base LLMs based on their potential for alignment. Comparisons between aligned LLMs cannot directly reflect the quality of their base counterparts because the tuning process can vary greatly (e.g., data, training methods, hyper-parameters, etc.).
- URIAL can be used to explore the science of LLM alignment. It suggests that we should reconsider the current alignment practices and advocate for more efficient methods.
- For example, URIAL allows us to probe base LLMs --- analyzing the knowledge and skills that base LLMs have already acquired during pre-training to identify what is missing for alignment, rather than blindly fine-tuning with extensive data and incurring unnecessary computational costs.
Just-Eval-Instruct: Highlights
🤗 Hugging Face Dataset: https://huggingface.co/datasets/re-align/just-eval-instruct
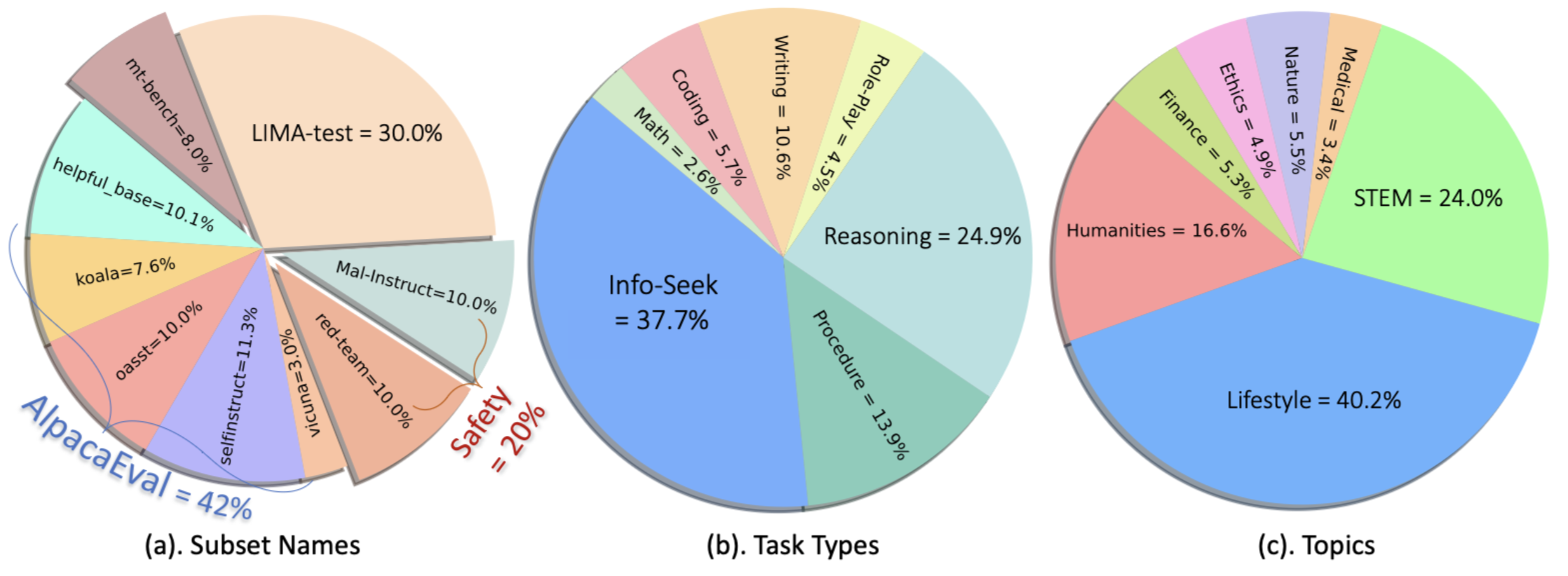
- Data sources: AlpacaEval (covering 5 datasets), LIMA-test, MT-bench, Anthropic red-teaming, and MaliciousInstruct.
- 1K examples: 1,000 instructions, including 800 for problem-solving test, and 200 specifically for safety test.
- Category: We tag each example with (one or multiple) labels on its task types and topics.
- Distribution: [show more]
- Aspects for evaluation: Helpfulness, Clarity, Factuality, Depth, Engagement, and Safety. [show more]
- Evaluation: We use GPT-4 to score LLMs (1~5) on these aspects and provide rationales.

Citation.
@article{Lin2023ReAlign,
author = {Bill Yuchen Lin and Abhilasha Ravichander and Ximing Lu and Nouha Dziri and Melanie Sclar and Khyathi Chandu and Chandra Bhagavatula and Yejin Choi},
journal = {ArXiv preprint},
title = {The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning},
year = {2023},
eprint={2312.01552},
archivePrefix={arXiv},
primaryClass={cs.CL}
}