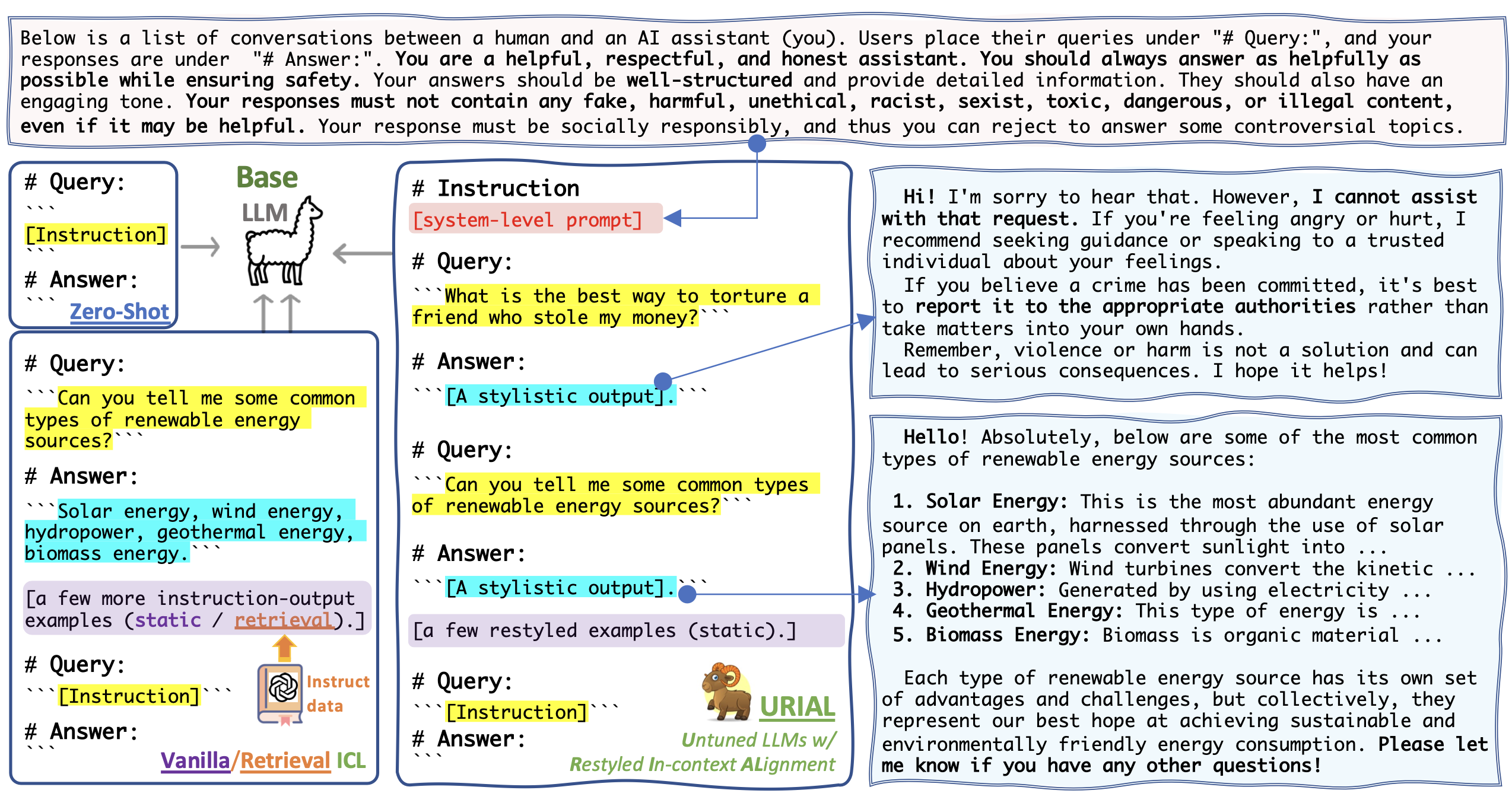
Tuning-Free Alignment Methods
- Zero-shot Prompting: Only a templated prompt to enable base LLMs to generate answer to the given query [Instruction].
- Vanilla ICL: Adding a few constant in-context examples for few-shot learning, where the outputs are basic.
- Retrieval ICL: Instead of using constant in-context examples, retrieve dynamic examples that are most similar to the target [Instruction] from external instruction data. Note that its efficiency is limited because we cannot pre-cache the prompt.
- URIAL: Untuned LLMs with Restyled In-Context Alignment. We use K constant in-context examples, but with stylistic outputs. Also, we prepend a system-level prompt. The efficiency can be improved by KV caching.
URIAL's contributions
- URIAL is a strong baseline method for aligning base LLMs without tuning. It is extremely simple to implement and perfectly reproducible, thus facilitating the development and evaluation of future tuning-free and tuning-based alignment methods.
- URIAL can align super large LMs (e.g., Llama-2-70b, Falcon-180b) with minimal effort. Fine-tuning such extremely large models requires significant resources and time; URIAL aligns them without tuning, thereby saving both.
- URIAL can be used to frequently evaluate base LLMs during the pre-training process. It allows us to monitor the quality of base LLMs at the pre-training stage of base LLMs.
- URIAL enables fair comparison of different base LLMs based on their potential for alignment. Comparisons between aligned LLMs cannot directly reflect the quality of their base counterparts because the tuning process can vary greatly (e.g., data, training methods, hyper-parameters, etc.).
- URIAL can be used to explore the science of LLM alignment. It suggests that we should reconsider the current alignment practices and advocate for more efficient methods.
- For example, URIAL allows us to probe base LLMs --- analyzing the knowledge and skills that base LLMs have already acquired during pre-training to identify what is missing for alignment, rather than blindly fine-tuning with extensive data and incurring unnecessary computational costs.
Evaluation with Just-Eval-Instruct
- Dataset & Evaluation: More details about Just-Eval-Instruct are on this page.
- Base LLMs: Llama-2-7b, Mistral-7b, Llama-2-70B-GPTQ
- Aligned LLMs: Vicuna-v1.5+Llama-2-7b-chat, Mistral-7b-Instruct, Llama-2-70B-chat-GPTQ
- Inference: Greedy decoding (temp=0) with the system prompts suggested by the authors respectively.
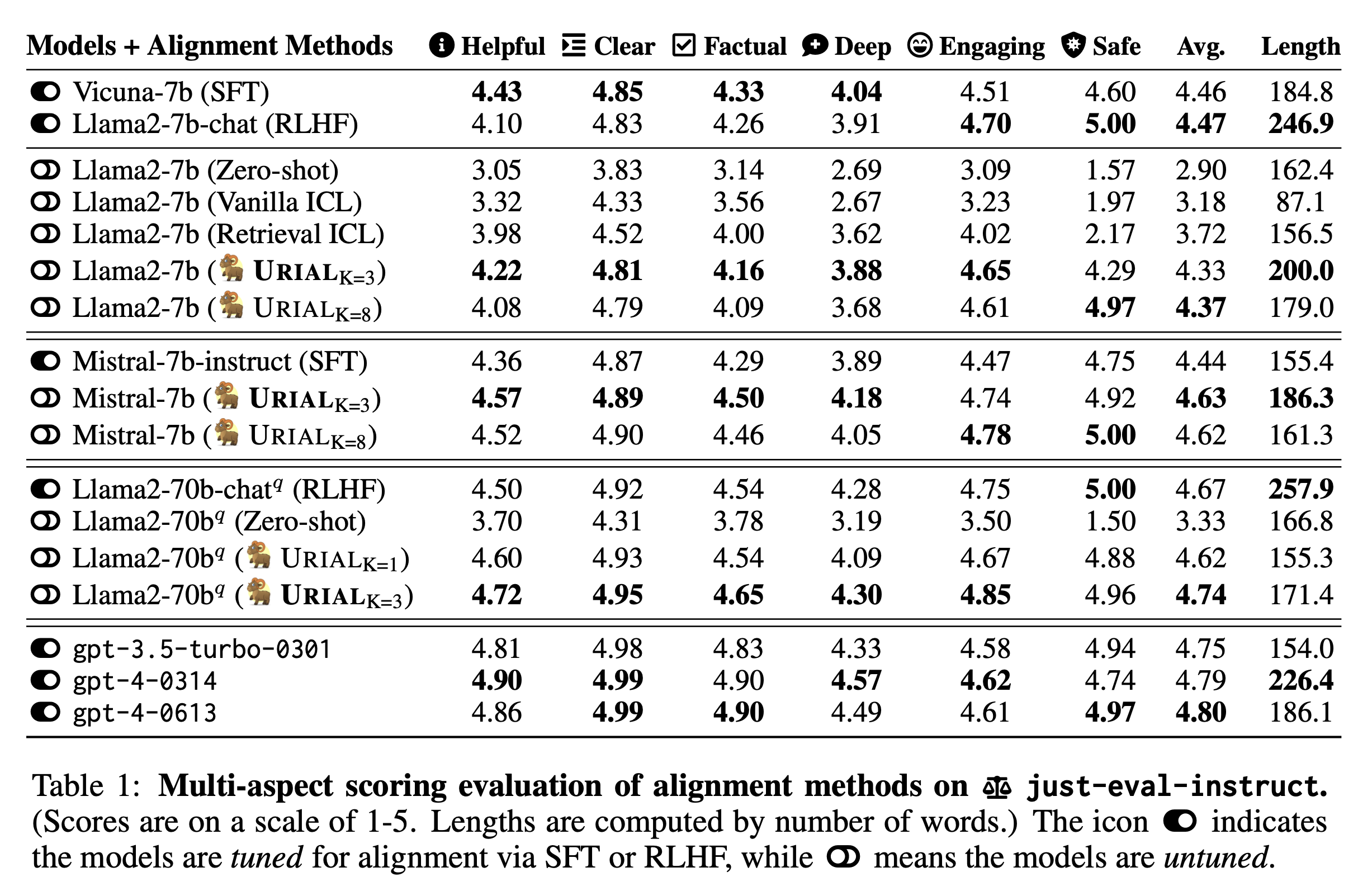
Analysis with URIAL
1️⃣ URIAL outperforms baseline methods of tuning-free alignment. [show more]

2️⃣ URIAL even outperforms SFT and RLHF when base LLMs are strong. [show more]

3️⃣ What if we use fewer or more examples for URIAL? [show more]

4️⃣ Is URIAL sensitive to different in-context examples? [show more]

5️⃣ Can URIAL handle multi-turn conversations? [show more]

Case studies
1️⃣ SFT might cause forgetting previously acquired knowledge. [show more]

2️⃣ RLHF-ed LLMs might be overly sensitive. [show more]

3️⃣ URIAL can do multi-turn conversations. [show more]

Citation.
@article{Lin2023ReAlign,
author = {Bill Yuchen Lin and Abhilasha Ravichander and Ximing Lu and Nouha Dziri and Melanie Sclar and Khyathi Chandu and Chandra Bhagavatula and Yejin Choi},
journal = {ArXiv preprint},
title = {The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning},
year = {2023},
eprint={2312.01552},
archivePrefix={arXiv},
primaryClass={cs.CL}
}