Alignment as Token Distribution Shifts.
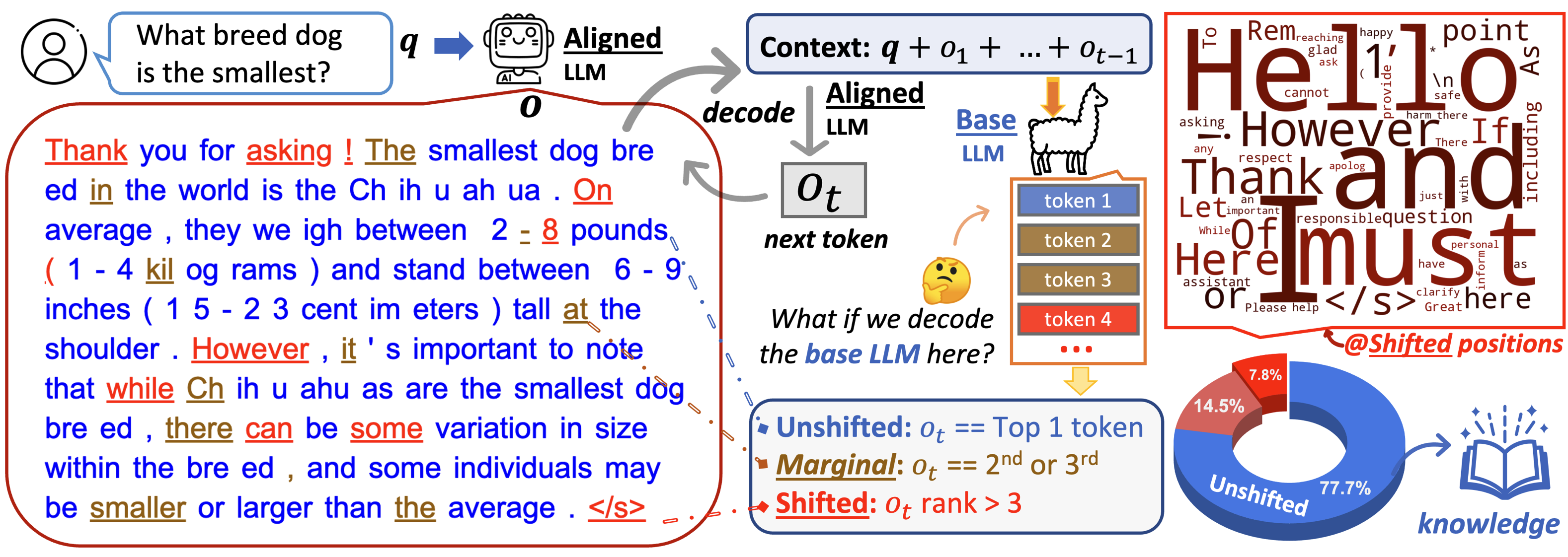
How can we know what are changed by alignment tuning (i.e., instruction tuning via SFT and preference learning via RLHF)?
Our analysis is based on token distribution shifts (TDS).
The pipeline is as follows:
Our analysis is based on token distribution shifts (TDS).
- We choose a pair of base and aligned LLMs (e.g., Llama-2 and Llama-2-chat).
- Given a user query (i.e., instruction) q, we first input it to the aligned LLM, and get its answer (via greedy decoding). We call this answer from the aligned model as o={o1, o2, ..., oT}. We save distribution at each position t, which is named Paligned.
- For each token position t, we use the context {q, o1, o2, ..., ot-1} as input to the base LLM (untuned), and get the token distribution of the base LLM for the next position t. Let's name this distribution Pbase.
- Now, we can analyze what are changed by alignment tuning through the difference between Paligned and Pbase at each position!
To easily analyze the TDS at each position, we define three types of positions based on the rank of aligned token (ot) in the token list ranked by Pbase:
- Unshifted positions: the aligned token (i.e., top 1 from Paligned) is also the top 1 token from Pbase
- Marginal positions: the aligned token is with in the 2nd or 3rd tokens ranked by Pbase.
- Shifted positions: the aligned token's rank is not within the top 3 tokens from Pbase.
You can visualize the token distribution shifts easily with our web demos:
- TDS demo: Llama-2-7b vs Llama-2-7b-chat (shifted ratio: 7.8%)
- TDS demo: Llama-2-7b vs Vicuna-7b-v1.5 (shifted ratio: 4.8%)
- TDS demo: Mistral-7b vs Mistral-7b-instruct (shifted ratio: 5.2%)
Key Findings:
- Alignment affects only a very small fraction of tokens. The base and aligned LLMs behave the same in decoding on most positions, where they share the same top-ranked tokens.
- Alignment mainly concerns stylistic tokens, such as discourse markers, transitional words, and safety disclaimers, which only take about 5-8% of the positions.
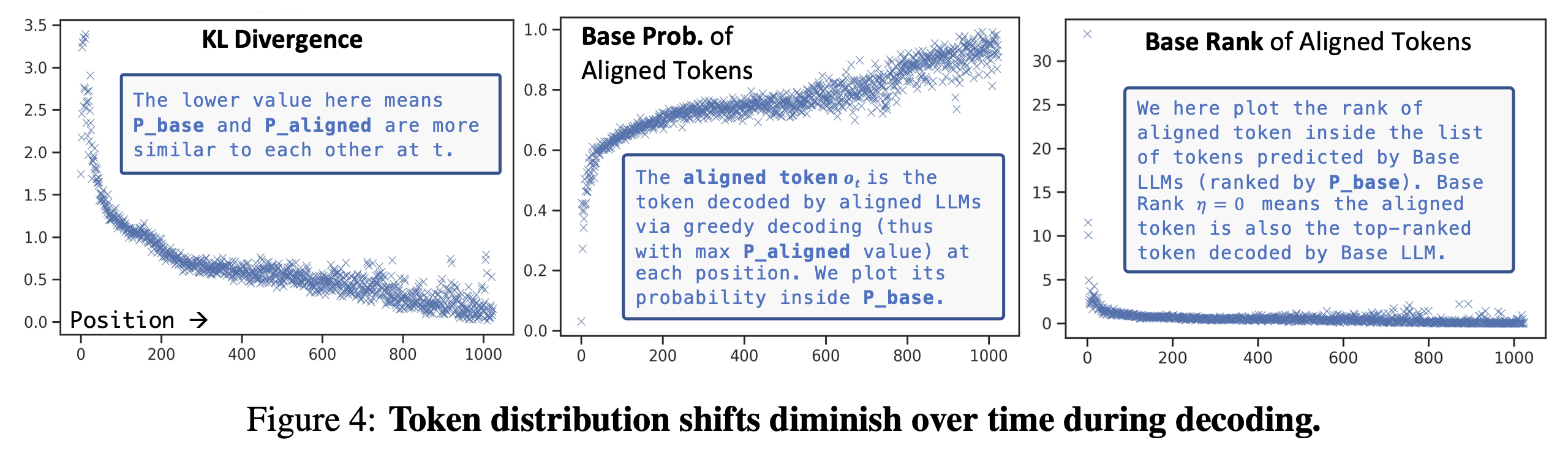
- Alignment is more critical for earlier tokens. For most positions, the aligned model's top-ranked token is within the top 5 tokens ranked by the base model.
- Base LLMs have already acquired adequate knowledge to follow instructions. They behave very similarly to aligned LLMs when given an appropriate context as a prefix.
Token Distribution Shift Analysis
1️⃣ Knowledge-intensive content originates from base LLMs. [show more]

2️⃣ Token distribution shits on different pairs of LLMs. [show more]


3️⃣ What does alignment tuning learn? [show more]

4️⃣ Token distribution shift diminish over time during decoding. [show more]

Citation.
@article{Lin2023ReAlign,
author = {Bill Yuchen Lin and Abhilasha Ravichander and Ximing Lu and Nouha Dziri and Melanie Sclar and Khyathi Chandu and Chandra Bhagavatula and Yejin Choi},
journal = {ArXiv preprint},
title = {The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning},
year = {2023},
eprint={2312.01552},
archivePrefix={arXiv},
primaryClass={cs.CL}
}